Unfortunately, many organizations are on the path to repeat one of the most consequential mistakes that we have made in this industry. AI Governance is now a critical leadership responsibility.
For years, executive leaders treated cybersecurity as a technical issue. It was convenient to tuck it away under Information Technology (IT) and it became someone else’s problem. They delegated it to specialists, discussed it only when budgets or incidents demanded attention, and assumed that technical teams could contain the risk.
Then the breaches became business disruptions. Regulatory consequences reached the CFO as well as the boardroom. Trust degraded, especially from customers. Operations stopped. Executives discovered that although they could delegate security work, they could not delegate accountability for the outcome. Tucking it conveniently inside of IT was no longer an option.
Artificial Intelligence (AI) is now following an eerily similar path, only much faster.
Many organizations still treat AI governance as a collection of technical controls, acceptable-use policies, legal reviews, and model assessments. They assign it to IT, data science, security, privacy, or compliance and assume those functions can govern the technology on behalf of the enterprise.
Simply put, they cannot.
Those teams can implement controls, evaluate models, monitor systems, and advise the business. They cannot independently decide which risks the organization should accept, which decisions should be influenced by AI or automation, where humans must retain authority, or who remains accountable when an AI-enabled processes have a negative impact.
Those are leadership decisions.
AI governance is not a technical specialization that executives can delegate. It is a leadership capability that executives must develop.
Leadership Cannot Outsource Accountability
I have spent much of my career moving between deeply technical responsibilities and executive leadership. I have worked in federal law enforcement technology, application architecture, offensive security, cybersecurity, the CISO function, the CTO function, and the CEO role.
Those experiences repeatedly reinforced the same lesson: technology may create the mechanism, but leadership creates the consequence.
For me, it took a while but that had to sink in as I lived my professional journey.
An algorithm does not determine whether an organization should use AI to evaluate employees, prioritize customers, detect fraud, approve transactions, recommend medical actions, or automate security responses. Leaders make those decisions.
The system may generate a recommendation, classification, or action. It does not absorb responsibility for the result. It simply generates an output.
A model cannot accept enterprise risk.
A chatbot is likely to not be able to explain a decision to an auditor.
An autonomous agent cannot appear before the board and defend the authority it was granted.
The human signature may become less visible as the footprints of AI and automation increase, but it does not disappear. It moves upward through the organization until it reaches the leaders who authorized these systems, established their boundaries (hopefully), funded their deployments, and accepted the risks at hand (again, hopefully).
AI Means More Than Generative AI
One reason organizations misunderstand AI governance is that most current conversations concentrate so heavily on Generative AI (GenAI). And the notion of “AI” in those conversations is incorrectly used to mean “GenAI”.
Large Language Models (LLMs), copilots, image generators, and conversational interfaces have made a subset of AI (GenAI) visible to almost everyone. They have also narrowed the discussion.
AI as a field extends far beyond generated text and images. Some organizations already use AI to:
- Detect financial fraud and account takeover.
- Score credit and insurance risk.
- Identify cyber threats and automate containment.
- Rank candidates and evaluate employee performance.
- Recognize faces, objects, behaviors, and anomalies.
- Predict equipment failures and optimize industrial processes.
- Recommend products, services, prices, and content.
- Route vehicles, shipments, and supply-chain resources.
- Support medical diagnosis and clinical decisions.
- Operate robots, sensors, and autonomous systems.
These systems may never generate a paragraph, but they can still shape someone’s employment, financial access, safety, privacy, or treatment.
Leaders who define AI governance as a policy for using ChatGPT will govern only the most visible layer of a much larger technology landscape.
Every system that predicts, accepts, rejects, classifies, recommends, prioritizes, optimizes, or acts should fall within the governance conversation. Yet, the limited understanding of where AI actually exists within organizations does not make that proper conversation possible.
AI Governance Begins With Ownership
Every material AI system needs an accountable owner. It doesn’t need a committee or some vague reference to “the business.”
A named leader must own the business purpose, risk, performance, and consequences of the system.
Technical ownership also matters, but it is not the same as business accountability. A data science team may build a model. A cloud team may host it. Security may monitor it. Legal may review it. None of those activities answers this central question:
Who has the authority to decide that this system should operate?
Ownership must extend across the AI lifecycle:
- Who approved the use case?
- Who authorized the data?
- Who selected or developed the model?
- Who defined acceptable performance?
- Who approved production deployment?
- Who monitors changes in behavior?
- Who can suspend the system?
- Who is accountable for the outcome?
When organizations cannot answer those questions, they do not have governance. They have the illusion of governance via distributed activity and no focused accountability.
Leaders Must Establish AI Risk Appetite
Many organizations speak about AI principles. Fewer define their AI risk appetite.
Principles describe what an organization values. Risk appetite determines what it will permit.
Effective leadership demands decisions around where AI may operate autonomously, where it may only recommend, and where it should not participate at all.
That requires decisions about:
- Which data AI systems may access.
- Which decisions may be automated.
- Which decisions require human approval.
- How much uncertainty the organization will tolerate.
- What level of explainability a use case requires.
- How much authority and/or autonomy an AI agent may receive.
- Which failures require immediate shutdown.
- When efficiency cannot outweigh safety, fairness, privacy, or trust.
For example, a fraud-detection model and an autonomous industrial controller should not operate under identical tolerance levels. Neither should a marketing assistant and a system that affects employment or access to employee resources.
Optimally, governance reflects potential consequence.
That judgment cannot come exclusively from a technical scoring system. It requires leaders who understand the organization’s culture, strategy, customers, obligations, operations, and values.
Human Oversight Must Be Real
“Human in the loop” has become a very overused phrase in AI governance.
Organizations often point to human review as evidence that a system remains under control. But placing a person near an automated decision does not guarantee meaningful oversight. Nor does it even reflect reality in some cases. The sheer volume of what AI powered systems can generate make human intervention questionable.
The human may lack sufficient time and/or information to challenge the system. The interface may encourage automatic approval. Time pressure may make careful review impossible. Employees may assume that the model is more accurate than they are. Responsibility may become so distributed that nobody feels empowered to intervene.
Realistically, human oversight requires more than a final approval button.
The reviewer must have:
- Enough context to understand the decision.
- Enough authority to reject or override it.
- Enough time to exercise independent judgment.
- Enough technical literacy to recognize uncertainty.
- Enough organizational protection to challenge the system.
Effectively, leaders must also consider automation bias. This is the natural tendency for people to trust the output of a system that appears objective, complex, or authoritative.
Ultimately, the human factor does not disappear when AI enters a workflow. It becomes more complicated.
Identity and Authority Form the AI Control Plane
Oddly, many AI governance discussions often focus on models and data while overlooking identity.
That is a serious mistake.
People build AI systems. Service accounts train them. Pipelines deploy them. Applications invoke them. Administrators change them. Agents increasingly act through them.
Every step involves an identity exercising authority.
An organization must know:
- Who or what is acting.
- Which identity the actor represents.
- What authority that identity possesses.
- What constraints exist on that authority.
- Who granted that authority.
- Whether the authority remains appropriate.
- Whether the identity remains trustworthy.
This becomes especially important with autonomous agents. An agent may retrieve information, call APIs, create accounts, modify configurations, communicate with customers, or initiate actions.
An agent should not receive unrestricted access simply because an authenticated employee launched it.
It needs its own identity, constrained privileges, defined purpose, limited duration, attributable owner, and immediate revocation path.
The organization should preserve the full chain of authority:
- Human initiator
- Agent identity
- Delegated permission
- Tool invocation
- Impacted resource
Without that chain, the organization cannot distinguish legitimate automation from compromised autonomy.
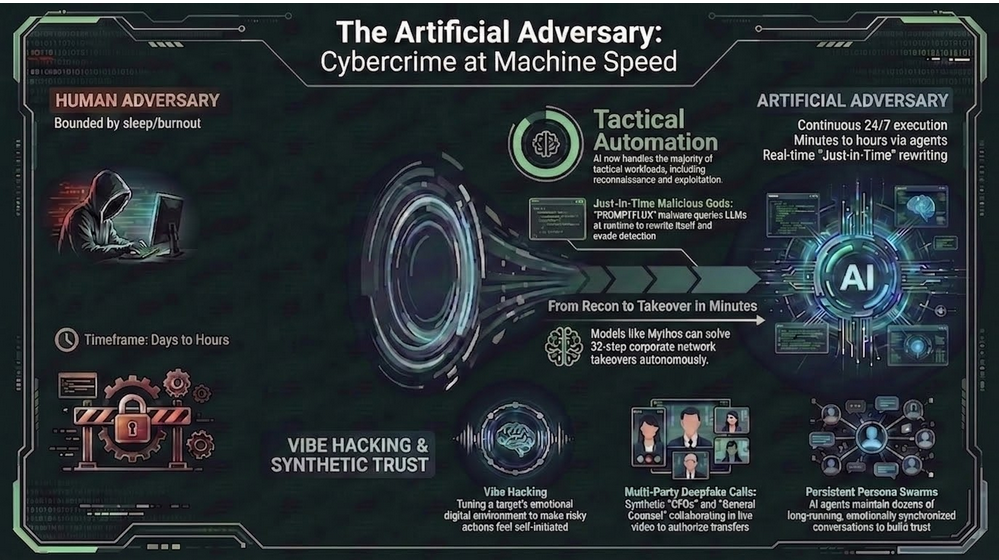
The Adversary Gets a Vote
AI governance cannot operate only under the assumption that people and systems will behave as intended.
Adversaries couldn’t care less about the rules. They will manipulate models, compromise identities, poison data, steal credentials, exploit integrations, and misuse legitimate functionality.
They will search for the gap between what leaders think the system does and how it actually behaves under pressure.
This is where an adversarial mindset becomes essential.
Leaders should not ask only, “Does the system work?” In a headspace where there are no limits, they should also ask:
- How could someone intentionally misuse it?
- What happens if its data becomes untrustworthy?
- Could a compromised identity change its behavior?
- Can an attacker manipulate the human reviewer?
- What authority could the system silently accumulate over time?
- How would we detect subtle rather than catastrophic failure?
- Can we stop it before we fully understand the incident?
Governance that assumes normal behavior is policy. And look at how effective policies are at stopping nefarious actors.
Governance that anticipates manipulation is a healthy step towards resilience.
AI Governance Must Become an Operating Rhythm
Organizations will not govern AI effectively through a policy, its annual review, or a one-time model assessment.
AI systems change. Their data changes. As do their users. Their integrations expand while authority grows. Their behavior may also shift as the environment around them changes. All of this is also happening at a rate of speed many organizations are not prepared for.
Governance must therefore become part of the organization’s operating rhythm.
Executive teams should receive recurring visibility into:
- The inventory of blindly discovered (approved and unapproved) AI systems.
- High-consequence use cases.
- Detected changes in model behavior or authority.
- Exceptions to established guardrails.
- Third-party and supply-chain dependencies.
- Identity exposure affecting AI environments.
- Evidence that human oversight remains effective.
The objective is not to force leaders to review algorithms. One is to ensure that leadership understands where the organization has transferred decision-making power to machines and what could happen if that transfer fails. Another is to build a cadence of readiness preparation so that negative surprises are minimized.
Five Questions Executive Leaders Should Ask Now
Every executive team should be able to answer five questions:
- Where is AI already influencing decisions or actions across the organization?
- Who owns each material AI system and remains accountable for its outcomes?
- Which decisions may AI make autonomously, recommend to a human, or never influence?
- Can we trace every important AI action to a human or non-human identity and its delegated authority?
- Can we suspend the system quickly when its behavior, data, identity, or operating environment becomes untrustworthy?
If leadership cannot answer those questions, the organization is not ready to deploy and/or scale AI responsibly.
Leadership Is the Ultimate AI Control
Technical teams will remain essential to AI governance. Organizations need skilled architects, data scientists, security professionals, privacy experts, engineers, and legal counsel.
But expertise does not replace executive accountability.
AI will compress the distance between a leadership decision and its technological consequences. A policy choice can become an automated workflow. A risk tolerance can become a model threshold. A poorly governed identity can become an autonomous actor.
The organizations that succeed will not necessarily be those that adopt AI fastest.
They will be the organizations whose leaders understand where AI should have authority, establish clear boundaries around that authority, demand attributable ownership, anticipate adversarial behavior, and retain the ability to intervene.
We eventually learned that cybersecurity was not merely a technology problem.
We should not need another decade of incidents to learn the same lesson about AI.
AI Governance is now a critical leadership responsibility, it is also a leadership test.
The outcomes will reveal who studied and prepared for that test.