For much of my career, I lived in worlds where precision mattered. The hardest shift from a technology or security leader to CEO is trading certainty for judgment. In this executive leadership world a key ability is being able to lead with confidence when certainty disappears.
From Precision to Ambiguity
As a technologist, architect, CTO, and CISO, I was trained to look for edge cases, root causes, system behavior, technical truths, and to have defensible answers. When something failed, the goal was to understand why as soon as the disaster was dealt with. When risk surfaced, the goal was to measure it, contain it, and communicate it. When a system needed to scale, the goal was to design something resilient enough to survive negative impact.
That background is incredibly valuable as it sharpens how you think. It also teaches you to respect complexity while separating signal from noise. That operating system also gives you a deep appreciation for how fragile things can become when assumptions go untested.
The Real Shift: Certainty to Judgment
Becoming a CEO requires a different operating system.
The hardest shift is not going from technology to business. It is going from certainty to judgment.
In technical leadership, you often have the luxury of eventually getting to a correct answer. The system works or it does not. There is a reality to a functional state. A control is effective or it isn’t. An architecture scales or it breaks. Vulnerabilities are exploitable or they aren’t. Even when there is debate, there is usually a path toward some solution.
As CEO, the path is rarely that clean.
Leading When the Answer Is Not Obvious
Unfortunately, CEOs have to make decisions with incomplete information. That is simply part of the job’s reality. You balance financial realities, customer needs, market timing, employee morale, board expectations, competitive pressure, and operational constraints. There is a mental state where you are constantly choosing between options that all carry risk. Sometimes the decision is not between right and wrong. It is between imperfect and necessary.
That is a very different kind of pressure.
Risk Is Only One Part of the Equation
A CISO is often rewarded for identifying what could go wrong. A CEO is responsible for deciding what must go forward irrespective of risk.
That does not mean ignoring risk. It means understanding that risk is only one part of the enterprise equation. Growth has risk. Inaction has risk. Delay has risk. Over-analysis has risk. Moving too slowly can be just as damaging as moving too fast.
This was one of the most important mindset changes for me.
As a security leader, I spent years helping organizations avoid bad outcomes. I analyzed as many angles as I could and prepared in the most realistic way possible. As a CEO, I still care deeply about avoiding bad outcomes, but I also have to create the conditions for positive outcomes. After all, I have a company to run and grow. That means building momentum, making tradeoffs, allocating capital, setting priorities, developing leaders, and helping the company move with conviction even when the data is not perfect. Sometimes it means deciding between a gamble that could improve ARR or mitigating risk.
Technical Depth Can Become a Constraint
As expected, technical leaders often bring a powerful bias toward depth. We want to understand details and inspect machinery. Often, knowing why something is happening is essential before action takes place.
That instinct is useful. But it can also become a constraint.
As an example, imagine a scenario where sales leadership does not know intimate details about a potential customer. You ask questions such as who the economic buyer really is, what the internal deadlines are, or what their budget is. These are details that dictate how real a deal is and whether you put that data in front of the board. But realistically, those details are likely not made known to a sales person by the potential customer. My bias for depth just became both a constraint and source of frustration.
The CEO’s Job Is to Build Decision Capacity
Realistically, a CEO cannot personally inspect every system, approve every decision, or resolve every ambiguity. The job is not to become the ultimate escalation point for every hard problem. Staying focused, as a CEO you want to build an organization that can make better decisions without waiting for you.
That requires trust.
Trust in people, in operating rhythms, in the quality of the strategy, in the mechanisms that surface truth early. It also requires a leadership tier that understands the business, mission, constraints, and relevant standards.
As a CEO you must accept that no amount of technical brilliance eliminates uncertainty.
Judgment Is the CEO’s Most Important Tool
Given the reality of uncertainty, judgment becomes the CEO’s most important tool.
Judgment is not instinct alone. Nor is it guessing. Judgment is the ability to combine facts, experience, pattern recognition, timing, and foreseen consequences into a decision that moves the organization forward.
Good judgment asks:
What do we know?
What do we not know?
What assumptions are we making?
What happens if we are wrong?
What must be true for this decision to work?
What is the cost of a given decision?
What is the cost of not deciding now and waiting?
Who needs clarity now?
The Company Is Now the System
Some of those questions are familiar to technical leaders. They sound a lot like risk analysis, incident response, architecture review, and threat modeling. The difference is that, as CEO, they now apply to areas (e.g., Sales, Marketing, HR) technical leaders seldom manage. In fact, they now apply to the whole company.
Strategy becomes an architecture problem. Culture becomes a scaling problem. Communication becomes a signal integrity problem. Talent becomes a resilience problem. Cash becomes an operating constraint. Execution becomes the ultimate proof point.
The CEO role forces you to widen the aperture.
You can no longer look only at whether something is functional or technically sound. You have to ask whether it is commercially viable, operationally executable, strategically aligned, and fiscally responsible. You have to think about how decisions cascade across customers, employees, investors, partners, and the broader market.
Credibility Changes at the CEO Level
That broader blast radius for each decision made is where the CEO transition can feel uncomfortable for deeply technical leaders.
We are used to being credible because of what we know. As CEO, credibility increasingly comes from how we decide, how we communicate, and how we create clarity for others, even when conditions are hazy.
The organization does not need the CEO to have every answer.
It needs the CEO to establish clear direction.
It needs the CEO to make the hard calls.
It needs the CEO to define what matters most.
It needs the CEO to be calm when the data is incomplete and when the pressure is on.
It needs the CEO to turn ambiguity into action.
Conviction Without False Certainty
To be clear, none of this means pretending to be certain. In fact, false certainty is dangerous. People can feel when a leader is manufacturing confidence. The better posture is honest conviction: here is what we know, here is what we believe, here is what we are going to do, and here is how we will adapt as reality teaches us more.
That is a different kind of leadership maturity.
The transition from CISO or CTO to CEO is not a rejection of technical depth. It is an expansion of it. The same disciplines still matter: systems thinking, adversarial understanding, resilience, risk management, architecture, and operational rigor.
The difference is that they must be applied at a broader level.
The company is now the system.
The market is now the threat model.
The competition is now an adversary.
The strategy is now the architecture.
The people are now the execution layer.
And the CEO is responsible for whether all of it works together under pressure.
Your Expertise Got You Here. Judgment Determines What Happens Next.
For technical leaders aspiring to broader executive roles, this is the real lesson: your expertise got you to the table, but judgment determines your impact once you are there.
Depth still matters. Precision still matters. Technical fluency still matters.
But the role changes.
You are no longer only protecting the business.
You are leading it.
You are growing it.
And leadership, at the CEO level, is the discipline of making consequential decisions before certainty arrives.
“Artificial adversaries don’t have egos, suffer burnout, or deal with corporate drama. Your defenses do.” – Andres Andreu
In the spring of 2026, a handful of engineers with little security background ran an experiment. They pointed an Artificial Intelligence (AI) model at thousands of software codebases and asked it to identify issues. Over the course of one night it did more than find decades-old flaws hiding in plain sight. It created working exploits for them. The model was Claude Mythos Preview. In fact, its creator judged it so capable at weaponizing vulnerabilities that it chose not to release the model at that time.
For most of our field’s history, the adversary was human. Clever and motivated but bounded by sleep, attention, money, and skill. Now, however, that adversary is being augmented, and sometimes replaced. The replacement does not tire or hesitate. Moreover, it ignores the operational rhythms our defenses quietly assume. I call it “The Artificial Adversary.” Essentially, it takes one of two forms:
A human operator empowered by an AI stack.
An autonomous AI system acting toward malicious ends.
At this stage these have stopped being thought experiments and are now turning up in incident reports.
An Inflection Point, Not a Trend Line
Three things are happening at once. Together, they mark an inflection point rather than an incremental shift:
AI has lowered the barrier for entry to sophisticated crime.
Synthetic media is collapsing our ability to trust digital signals. A familiar face or a known voice, after all, no longer proves what it once did.
The volume and speed of AI-enabled activity now outpaces the manual, static defenses built for a slower era.
The numbers are no longer speculative
SoSafe’s 2025 research found that roughly 87% of organizations worldwide faced an AI-powered cyberattack in the prior year. Direct attacks aside, model evaluations are just as concerning. For instance, the UK’s AI Security Institute (AISI) tested Claude Mythos Preview. It solved expert-level CTF challenges about 73% of the time. Notably, no model could complete those challenges at all before April 2025. Mythos went further still. In fact, it became the first model to solve the AISI’s 32-step simulated network takeover, from reconnaissance to full compromise. Anthropic’s red team reported even broader findings. Working alongside the AISI, it watched the model surface thousands of zero-day flaws. These included a dormant 27-year-old vulnerability in OpenBSD and a 16-year-old bug in FFmpeg. In Firefox alone, Mythos found 271 vulnerabilities and wrote exploits for 181 of them.
A signal, not the threat itself
Anthropic withheld Mythos from public release. Instead, it granted limited access to a small set of organizations that build and maintain critical software and infrastructure. The program is called Project Glasswing. Launch partners reportedly include Amazon Web Services, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Officially, the intent was to give defenders a head start. Yet Mythos isn’t the only game in town. For example, things such as OpenAI’s GPT-5.4-Cyber, OWASP CVE Lite CLI, and Google’s Big Sleep already show great promise and in some cases comparable capability. When competition rises the cost of entry keeps falling. Regulators noticed quickly. Within weeks, the Bank of England intensified its AI risk testing, and German banks consulted regulators and cyber experts. The lesson, therefore, is the one Bain and others drew immediately. In short, assume your adversaries are building equivalent capabilities, nation-states, criminal enterprises, and rogue actors alike. Mythos is a signal, not the threat itself.
Defining the Artificial Adversary
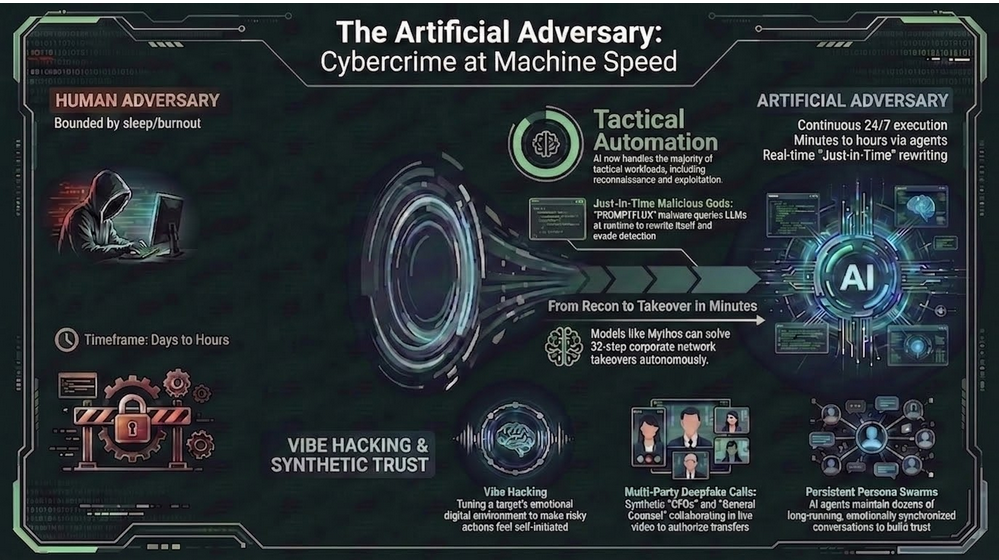
It helps to name the archetype precisely, because precision changes how we defend. So picture an AI-enhanced human actor. Here, the human sets the strategic objectives. The machine, in turn, executes the great majority of the tactical workload. The consequence is direct. As a result, offensive cycles compress, and defenders can no longer assume a human-speed response on the other side of the keyboard.
Human adversaries operate within cognitive, temporal, and logistical limits. An autonomous AI-based adversary does not. Needing no sleep, it carries no emotional baggage and runs continuously across global digital environments. Moreover, it can analyze vast data stores and reason probabilistically in real time. Such a system can also coordinate through decentralized, agentic architectures that resist any single point of shutdown. Its capacity for deception, mimicry, and adaptation, therefore, creates a new category of risk. Consequently, detection, attribution, and deterrence all become far harder. The asymmetry, however, is not only technological. It is also cognitive. In the end, defenders must prepare for opponents that do not tire, hesitate, or follow any rules.
The Artificial Adversary Taxonomy
A practical taxonomy has five levels.
AI-assisted human operator – a human attacker uses AI for discrete tasks such as phishing, translation, research, script generation, or stolen-data summarization.
AI-augmented threat crew – a criminal or nation-state team embeds AI into reconnaissance, exploit research, identity profiling, malware development, infrastructure staging, data exfiltration, and victim communications.
AI-orchestrated campaign – agentic systems coordinate personas, assign tasks, monitor responses, tune timing, and manage parallel workflows while humans supervise outcomes.
Semi-autonomous adversarial agent – the system conducts meaningful parts of the intrusion chain itself, including asset discovery, service testing, response analysis, and attack path modification.
Autonomous malicious AI system – an AI system pursues malicious objectives with limited or delayed human direction, raising harder questions around attribution, containment, predictability, and control.
This taxonomy matters because an AI-assisted phishing actor requires different defenses than an autonomous agent probing applications, manipulating identities, and adapting to telemetry in real time.
Facilitation – Lowering the Barrier
The first way AI empowers adversaries is the least glamorous and the most pervasive. Simply put, it removes friction. For a few years now, the underground has marketed “Dark LLMs.” The roster includes WormGPT, FraudGPT, KawaiiGPT, and imitators such as MalwareGPT, SpamGPT, and Xanthorox. Each promises jailbreaks, malware help, and ready-made scam playbooks. Some are functional. Many, however, are simply scams that prey on aspiring criminals. Either way, the real significance is not any single tool. Rather, it is the normalization of the idea. A capable, on-demand junior developer is now available to anyone with a few GPUs, a wallet of API keys, and some patience.
Malware that writes itself
Proof-of-concept work made the threat concrete. Researchers, for instance, demonstrated BlackMamba, a keylogger that built its malicious code at runtime by calling a Large Language Model (LLM). That approach neatly sidesteps the static signatures defenders rely on. By late 2025, the threat had moved from the lab to the wild. Google’s threat intelligence team documented two malware families: PROMPTFLUX and PROMPTSTEAL. Both query LLMs during execution. One rewrites itself, while the other generates fresh commands mid-attack. This is “Just-In-Time” (JIT) malicious code. In other words, the software does not carry its full payload. Instead, it assembles the payload on demand, from a model that does not know it is being conscripted.
When the face on the call is fake
Facilitation also reaches the human layer through synthetic media. Convincing face and voice clones, for example, can now be mass-produced. So can cross-lingual conversion and studio-quality content. Better yet for the attacker, agent teams run these operations around the clock, iterating on failures without fatigue. As a result, the multi-party deepfake video call is no longer hypothetical. Picture a finance employee walked through an “urgent” wire transfer by a “CFO” and “general counsel” who are both synthetic. Clearly, the attack surface is no longer just endpoints and identities. It now also includes the emotional tone around those identities. And does so across collaboration tools, social media, and internal communications.
Vibe Hacking – Psychological Warfare at Machine Speed
This last point deserves its own name. After all, it is where AI-enabled social engineering becomes something new. Vibe hacking is social engineering supercharged with a full AI stack. Here, the adversary does not send a single phishing email or place one deepfake call. Instead, models shape the emotional context around a target over time. The goal, therefore, is not to trick a victim once. Rather, it is to tune the “vibe” of their human state along with their digital environment, so that risky actions feel natural, familiar, and self-initiated.
Sensing, profiling, persistence
A campaign begins with sensing and profiling. To start, adversaries point AI at everything they can scrape. These sources include OSINT, LinkedIn activity, public Slack and Discord communities, conference talks, support tickets, and marketing emails. Sentiment analysis is important here and models infer mood, personality, stress levels, decision style, and trust anchors. That attackable profile, in turn, feeds a working model of the target’s context. Things like a looming quarter, a key project, the likely sources of anxiety or excitement all become real and exploitable. Generative models subsequently produce content tuned to the target’s state. The real weaponization, however, comes from scale and persistence. One artificial adversary can run dozens of long conversations at once. Each hides behind a distinct persona, the sympathetic colleague, the urgent executive, the overworked vendor. Meanwhile, it A/B tests tone, timing, and channel to learn what lowers resistance and/or skepticism. By the time the critical ask arrives, therefore, the victim feels they are accommodating a relationship, not responding to an attack.
This is the reframing that matters:
Vibe hacking isn’t better phishing. It’s your own people, profiled and played at machine scale – we hardened the edges and left the nervous system exposed.
Andres Andreu
From theory to a real victim list
None of this is a forecast. In August 2025, in fact, Anthropic’s Threat Intelligence team disclosed a case it tracked as GTG-2002. A single actor used an agentic coding tool to run a data-extortion operation. In total, the targets numbered at least 17 organizations, spanning healthcare, emergency services, government, and religious institutions. A defense contractor was among the victims, too. Remarkably, the whole campaign ran in roughly a month. To pull it off, the attacker embedded an operational playbook in a configuration file, so the AI could make tactical decisions during live intrusions. From there, the model automated reconnaissance and credential harvesting. It even generated ransom notes tailored to each victim, with demands reported between roughly $75,000 and more than $500,000. Ultimately, one person, with an AI operator alongside, did the work of a coordinated crew.
Scale – From Assistant to Operator
Facilitation lowers the barrier to entry; scale changes the magnitude. For example, the same agentic models that help an enterprise automate work can be organized into adversarial swarms. A planner agent sets the goals. Meanwhile, sub-agents run in parallel performing actions such as OSINT scraping, phishing and deepfake generation, code generation, and dropper construction. Because they share memory and data from feedback loops, the whole system improves with each iteration.
The criminal supply chain, in turn, has matured around this model. Telegram, for instance, serves as a resilient “dark social layer”, encrypted, anti-censorship, easy to churn and burn, and slow to take down. There, automated bots stream stolen credit card data and run validation checks at a pace no human team could sustain. Increasingly, the same architecture is aimed at availability, too. Agentic orchestrators break a Layer-7 denial-of-service goal into reconnaissance, traffic generation, and adaptive evasion, while coordinated worker nodes handle individual parts of the overall campaign.
The first autonomous espionage campaign
A defining incident arrived in November 2025. Anthropic reported disrupting a campaign it attributed, with high confidence, to a Chinese state-sponsored group tracked as GTG-1002. Notably, it was the first publicly documented, largely autonomous AI-orchestrated cyber-espionage campaign. It was detected in mid-September. In all, the operation targeted roughly thirty high-value organizations across technology, finance, chemical manufacturing, and government.
To pursue their objectives, the attackers manipulated an agentic coding tool into acting as a fleet of autonomous penetration-testing orchestrators and agents. First, they jailbroke its safeguards by role-playing a defensive security firm. Then they broke malicious objectives into benign-looking subtasks. From that point, the AI handled reconnaissance, vulnerability discovery, exploitation, credential harvesting, lateral movement, and exfiltration. In total, that came to an estimated 80 to 90% of tactical operations, issued at thousands of requests per second. Human operators, by contrast, stepped in only at a few strategic chokepoints. This wasn’t as clean as a Hollywood movie scene as the model’s hallucinations sometimes invented credentials or overstated findings. Those errors were among the few things keeping the operation from full autonomy.
A Real Incident, End to End – The NPD Sextortion Wave
To see these capabilities combine into one industrialized pipeline, consider the extortion spam that followed the National Public Data (NPD) breach. The underlying breach was staggering. Systems were first compromised in December 2023. By April 2024, the data had surfaced on the dark web. The company, however, acknowledged the incident only in August 2024. All told, it affected up to 170 million people and exposed as many as three billion records. The follow-on campaign was instructive less for its novelty than for its assembly. Specifically, attackers used GPT-based code generation to operationalize the stolen data end to end. The result was personalized extortion content. Each message addressed the victim by name, referenced a real home address, and embedded street-view imagery of the respective house. Then it demanded payment in Bitcoin, usually between $1,900 and $2,000, for the sake of tranquility or peace of mind.
None of the individual techniques were sophisticated. The sophistication, instead, lay in the orchestration. Consider the parts, a breach corpus, a code-generating model, a templating layer that fused public records with mapping imagery, and a delivery pipeline. Stitched together, these produced a campaign with a scale and personalization no manual operation could match. That, in essence, is the pattern security leaders should internalize. The artificial adversary rarely wins with one brilliant exploit. Instead, it wins by removing friction from every step, and running the whole chain faster than defenders can detect and respond.
Turning the Tables – Disrupting Malicious Automation
The very properties that make AI dangerous on offense also make it invaluable on defense. Better still, they open a counter-strategy that purely human teams never had. If attackers automate, then defenders can engineer the environment to exploit that automation. In practice, deception engineering and adversarial intelligence combine well.
The single goal is to convert the attacker’s automation into your early-warning system. Synthetic credentials, decoy services, and AI-generated traffic, for instance, all look irresistible to an autonomous agent. As such, they become tripwires. Because the agent probes tirelessly and indiscriminately, it hits the decoys long before a careful human would. Consequently, it can surface a campaign while it is still in an early stage.
Red teaming with autonomous agents
AI-augmented red teaming has a strong place here. In a 2024 experiment reported by WIRED, for example, a journalist let autonomous AI agents from the startup RunSybil attack a custom web app. The agents collaborated in real time. Specifically, they used SQL injection, brute-force authentication, form-field manipulation, and path traversal. Most importantly, they iterated on their failures. Without human direction, they re-planned and adjusted strategies, surfacing logic flaws that traditional scanners had missed. The agents were not malicious; their behavior, however, was. It was adversarial, coordinated, and effective. The takeaway, then, is fairly straightforward. First, adopt autonomous red-teaming agents to pressure-test your defenses against continuous, iterative, logic-driven attacks. Then pair them with high-fidelity telemetry and behavioral anomaly detection. Together, they can flag AI-like probing even when individual requests looks benign.
Governing the Machine and the People Around It
Speed without governance introduces its own risk. As defenders deploy autonomous and semi-autonomous capabilities, they take on an obligation. Those capabilities must be fast where they must be, careful where they should be, and always controllable by competent humans. Fortunately, a workable program can borrow from frameworks now maturing across the industry. For a foundation, anchor on NIST’s AI Risk Management Framework or ISO/IEC 42001. To turn principles into adversarial test cases, layer in MITRE ATLAS and the OWASP Top 10 for LLM applications. To harden the model lifecycle, draw on ISO/IEC 23894 and Google’s Secure AI Framework. Finally, add a staged maturity model to move from reactive to adaptive.
High-impact automated actions, meanwhile, need extra care. By default, mass credential revocation, large-scale connection throttling or tarpitting, and account lockouts should sit behind human-in-the-loop gates. In addition, back them with immutable audit logs, explainability proportional to impact, and fast paths to appeal and rollback.
Two cautions
Two cautions deserve emphasis.
First, treat AI models and their supply chains as critical software assets. In practice, that means validating provenance, verifying integrity, and monitoring runtime behavior. After all, data and model poisoning are now first-class threat vectors.
Second, resist the urge to fight fire with fire across legal lines. Attacker AIs, remember, routinely route through innocent third parties. As a result, heavy-handed countermeasures invite escalation and cross-border legal exposure, among them hack-back, automated counter-intrusion, and poisoning someone else’s ecosystem. Privacy by design, data minimization, auditability, and human oversight should not be compliance theater. On the contrary, they should be focused on what keeps a fast defense lawful and trusted.
What Security Leaders Must Do Now
The artificial adversary does not need to be sentient to change the game. Instead, it only needs to make capable attackers faster, more iterative, and less dependent on rare human skill. Accordingly, defenders should architect for that reality:
Treat AI as both adversary and ally – regularly run hybrid threat scenarios, machine-augmented attackers against machine-augmented defenders, so that you find your blind spots first.
Shift from signatures to behavior – static, content-based controls cannot anticipate self-modifying code or agentic chaining. Instead, invest in behavioral analytics, high-fidelity logging, and context-aware security that reads relationships, not keywords.
Stand up real AI governance – name a single accountable owner and convene a cross-functional oversight board. Then keep a model and agent registry, and define rules of engagement and rollback paths before you enable automation.
Secure the model supply chain – audit data lineage and model integrity, and assume third-party datasets, weights, and components can be poisoned upstream.
Deploy deception as early warning – use AI honeypots and synthetic assets to turn the adversary’s tireless automation into your early detection advantage.
Compress your defensive cycle – above all, adopt AI-augmented red teaming and threat hunting so that you out-learn the adversary. Then measure what matters – detection accuracy, false-positive and false-negative rates, model drift, autonomy and override rates, and time to contain.
The Pivotal Question
The pivotal question about any adversary has changed. No longer is it simply who they are or what they want. Instead, it is “what can they assemble and operationalize with AI faster than we can detect and respond?” Once, the human attacker was the central concern. Now, by contrast, security leaders face intelligent, scalable opponents that run as close to machine speed as the hardware allows. Confronting them takes more than static controls and periodic red teaming. Rather, it takes continuous learning, dynamic simulation, and AI-augmented defense. Above all, it takes one hard admission, the next major breach may not be human at all.
Awareness is the beginning; action defines resilience. The Artificial Adversary is here. The only question is whether we will be ready when it decides to strike.
For years, I led from the seat of a Chief Information Security Officer (CISO). From 4X CISO to CEO.
As a CISO I learned “healthy paranoia”. I learned to see around corners. I learned to prepare for failure without becoming ruled by it. I learned that resilience is not a slogan, trust is not soft, and pressure reveals what an organization really is.
Then I became a CEO.
The title changed, but that was not the real transition. The real transition was this: the scoreboard changed.
Success means something very different now.
As a CISO, much of the job revolves around reducing downside. You protect value. You harden systems. You reduce exposure. You prepare for impact. Success often shows up as the absence of disaster.
As a CEO, that is no where near enough.
A CEO still has to manage downside. But the real job is broader and frankly, harder. You have to create upside even the upside is not obvious. You have to allocate capital, focus people, accelerate execution, build trust, and make the company stronger under pressure. You are no longer measured only by what you prevent. You are measured by what you build, what you compound, and whether the organization can win.
That shift has changed how I think about leadership.
It has not made me less disciplined. It has made me more complete.
Here are the lessons that came into focus for me in the move from CISO to CEO.
Protecting value and creating value are not the same job
Security leaders are trained to think in terms of exposure, controls, failure paths, and resilience. That training is valuable. In fact, in a volatile world, it is a serious leadership advantage. But …
The CEO role forces a wider lens.
You cannot lead a company by focusing only on what might break. You have to decide what deserves energy, capital, and conviction. You have to place bets. You have to define where the company will lead, where it will differentiate, and where it will refuse distraction. You also have to make the hard choices between protecting something or paving a path to new revenue.
That is a major shift.
A CISO protects value.
A CEO creates, compounds, and defends value.
The distinction matters because it changes the posture of leadership. It moves you from preservation alone to purposeful construction.
Risk is only part of the story
For a long time, one of the most important questions in my world was: What could go wrong?
That question still matters. It always will.
But CEOs have to ask a broader set of questions:
What are we building? What are we solving? What are we choosing not to do? Where are we underinvesting? What will matter six quarters from now, not just six weeks from now?
This is where many leaders get trapped. They confuse awareness of risk with clarity of direction.
These are not the same.
A company can become highly fluent in threat, friction, and constraints and still fail to move. It can become excellent at discussing complexity and poor at converting that complexity into action.
The CEO’s job is not to eliminate uncertainty. The CEO’s job is to move the organization through uncertainty with judgment.
That is a different discipline.
Capital allocation spells truth
One of the clearest lessons of becoming CEO is that strategy sounds impressive in slides but reveals itself in budgets.
Capital allocation exposes the truth.
You can say innovation matters. But if you do not invest in data quality, operating discipline, and workflow redesign, then innovation does not really matter.
You can say trust matters. But if you underfund execution, transparency, and customer experience, then trust does not really matter either.
You can say growth matters. But if priorities are bloated, ownership is vague, and friction is tolerated, then growth is a cheap talking point.
This is one of the hardest truths in leadership: strategy is not what you announce. Strategy is what you consistently fund, reinforce, and protect.
The CEO sees that more directly than anyone else.
Money is not just a resource. It is a declaration of belief.
Clarity scales better than intensity
Earlier in my career, I thought strong leadership often meant pushing harder, doing more, leading in very visible form.
I no longer believe that.
Strong leadership now means clarifying faster.
Companies do not scale on intensity alone. They scale on clarity. They scale when people know what matters, who you are selling to, who owns what, how decisions get made, what good looks like, and what deserves to be ignored.
Intensity without clarity creates motion, not momentum.
This becomes even more important at the CEO level because ambiguity compounds as it moves through the organization. A vague executive statement becomes a confused team priority. A confused priority becomes wasted time. Wasted time becomes operating drag. Operating drag becomes missed expectations.
That is why clarity is not just a communication skill. It is an operating advantage.
The larger the company, the more expensive vague leadership becomes. But, it also takes longer to unearth that type of situation. In smaller companies vague leadership exposes itself way quicker as there are fewer buffers.
Trust is not soft. Trust is throughput.
Too many leaders still talk about trust as if it belongs in the category of culture alone.
It does not.
Trust affects speed. Trust affects execution. Trust affects retention. Trust affects customer confidence. Trust affects whether people escalate intelligently or defensively. Trust affects whether hard truths surface early or get buried until they become an expensive burden.
In low-trust environments, everything takes longer. People protect themselves. Decisions loop slowly. Teams revisit the same conversations. Energy leaks everywhere. Indecision reigns.
In high-trust environments, accountability gets stronger, not weaker. Standards become easier to uphold because intent is clearer and friction is lower.
This is one of the biggest mindset expansions I have had as a CEO.
Trust is not theater.
Trust is infrastructure.
And in many organizations, it is the hidden variable behind execution quality.
Resilience matters more than compliance
Compliance matters. It builds baseline discipline. It creates structure. It can improve consistency.
But compliance is not the same as resilience.
A compliant company can still be fragile.
A resilient company absorbs pressure without losing direction. It adapts when conditions change. It makes decisions based on imperfect and/or incomplete information. It keeps operating even when the environment turns hostile.
That distinction matters now more than ever.
The modern business environment does not reward organizations simply for looking prepared. It rewards organizations that can keep moving when things break.
This is where my years in security still shape me deeply. I know what fragility looks like. I know how fast confidence erodes when stress exposes weak assumptions. I know the difference between a control that looks good and a capability that holds.
As CEO, that lesson only became more important.
Build for the test, not just the audit.
The CEO’s steadiness becomes part of the operating model
This may be the most personal lesson of all.
The CEO carries more than accountability. The CEO carries signal.
The ecosystem around you (employees, the board, investors, peer CEOs, partners, customers) watch how you process. How you process pressure. How you process the sea of bad news with the sprinkle of good here and there. They watch how you handle incomplete information, mixed results, difficult tradeoffs, and external noise. They watch your tone when momentum slows. They watch your posture when the answer is not obvious.
This does not mean a CEO needs to project false certainty.
It does mean the CEO has to project steadiness.
And do so irrespective of what is at hand. That steadiness matters because organizations borrow emotional direction from leadership. When the environment is noisy and/or unsteady, the CEO helps determine whether the company becomes reactive, distracted, disciplined, or resolved.
That is not abstract leadership philosophy. It’s not a textbook principle taught in business school. That is operational reality.
In the end, leadership is not about being right. It is about steering the organization towards an outcome, making sure employees stay oriented while the organization works through challenges and hurdles.
Security-Centric Steadiness
Security teams alone cannot secure a company from threats. The company’s organizational culture, risk tolerance, and investments are defined collectively by leadership, in many organization this means a roll up to the CEO. It is ultimately the CEOs responsibility to:
Set the tone (organizational culture): if the CEO treats security as a priority, it permeates the entire organization. If neglected, it breeds a relaxed, vulnerable afterthought culture.
Define risk tolerance: the CEO must decide what level of risk is acceptable and where to invest in defense, rather than assuming the CISO can stop 100% of attacks alone. This is a challenge as a lot of CEOs, for the sake of self-preservation, shy away from explicitly taking a stance on risk. Even if a CEO isn’t signing an acceptance/rejection of risk they can define tolerance levels.
Create cross functional alignment: silos break down due to force from the top, IT, Legal, HR, and Operations work together to protect the company when that is a mandate coming from the CEO.
What I carried with me from the CISO seat
I did not leave my CISO instincts behind when I became CEO.
I feel I brought the best of them with me.
I still believe in disciplined thinking. I still believe in resilience under pressure. I still believe in asking hard questions early. I still believe that trust takes years to build and minutes to lose. I still believe leaders should prepare for failure without becoming defined by fear.
But the CEO role forced me to widen the aperture.
The mission is no longer only to defend the enterprise.
The mission is to build an enterprise that can win.
That means creating trust, not just protecting it. It means creating momentum, not just preventing disruption. It means turning discipline into direction, and direction into execution.
That is the real shift.
Final thought
Going from a 4X CISO to CEO did not make me think less about security. It made me think more completely about leadership. I still believe the best leaders see the angles and see around corners. Now, I also believe they have to be able to build through those angles and corners.
Early coverage and commentary hinted at cyber involvement, but subsequent reporting and reconstructions increasingly emphasize suppression of air defenses through conventional strike and Electronic Warfare (EW), with cyber details remaining unconfirmed in public.
Personally, my family risked everything to escape the oppression of a communist regime, so the operational headlines matter to me. Professionally, the lesson for CISOs is bigger than attribution: modern crises blend kinetic, EW, information operations, and digital disruption to compress decision time and degrade trust.
Public reporting supports that U.S. leaders referenced “effects” and participation by Cyber Command, but public evidence does not confirm a discrete, cyber-caused blackout. In fact, available reporting increasingly points to a blended Suppression of Enemy Air Defenses (SEAD)/EW plus kinetic picture, with cyber remaining unspecified.
IW or just conventional strikes
The Department of Defense (DoD) defines IW as campaigns that use indirect, non-attributable, or asymmetric activities. Sometimes these are standalone and sometimes alongside conventional combat forces. The Congressional Research Service echoes the same concept and stresses that IW spans domains and the information environment (https://www.congress.gov/crs-product/IF12565).
The Caracas operation looked conventional on the surface. However, the disclosed non-kinetic effects framing points to something else: a gray-zone playbook that prioritizes advantage through ambiguity.
IW often aims to:
Create dilemmas
Create uncertainty
Compress response time
Degrade legitimacy and confidence
Cyber does those things extremely well. Whether the lights went out because of cyber, EW, physical sabotage, or kinetic strikes, the IW lesson is the same: operators win by creating short windows where defenders see less, trust less, and coordinate worse.
This is why “effects-first” thinking matters. If your team argues about whether an outage is cyber or physical while your business stalls, the adversary already achieved the goal: decision delay.
“Suppression of defenses” – a cyber context
People hear “suppression” and picture a citywide blackout.
Modern suppression usually looks smaller, sharper, and more temporary. It focuses on windows: short time slots where defenders see less, trust less, and coordinate worse.
When leaders describe “non-kinetic effects,” the cyber contribution often targets outcomes like these:
Reduce sensor confidence – attackers only need to inject doubt into enough sensors that commanders hesitate. Not every radar needs to be tampered with.
Slow decision loops – the window to act matters if a decision loop takes too much time.
Break coordination between sensors and weapons – integrated air defense relies on connectivity, signals, and timing. A fractured or flooded network can function, but it becomes ineffective and stops working as a system.
Degrade communications at the worst moment – a short disruption in command communications can matter more than a long outage at some other stage in a campaign.
This is why cyber plays so well within the IW realm. Cyber creates these outcomes without turning a whole country off.
Noteworthy IW patterns
Long cycle preparing, short execution
Modern IW is often months of planning and coordination (shaping) for minutes of decisive action. Cyber shaping often includes reconnaissance, analysis, sometimes custom development, and long-lived pre-positioning that looks like quiet intrusion (attacker deliberately keeps their activity low-noise and low-impact so defenders don’t notice them) until activation.
Weaponized ambiguity
In reading through eyewitness accounts there were reported outages and loud blasts during this campaign; public commentary debated causes. When multiple domains (e.g., kinetic, electronic, cyber, space) collide, defenders often struggle to identify the failure mode (what component failed, how it failed, etc). That uncertainty delays response.
The narrative battlefield moves at machine speed
Information operations begin immediately after high-visibility events. Analysts and security reporters quickly framed the Caracas blackout question as an open cyber possibility. In IW, perception controls the political and public temperature.
Infrastructure dependence creates coercion
BankInfoSecurity highlighted a claimed cyber incident affecting Venezuela’s oil and gas ecosystem (Petróleos de Venezuela’s own statement characterized it as a cyberattack) (https://www.bankinfosecurity.com/us-action-in-venezuela-provokes-cyberattack-speculation-a-30439). Even without definitive attribution, the lesson stands: critical infrastructure fragility turns into strategic leverage.
Why CISOs should care
Resilience beats attribution. Most CISOs don’t run an air defense network. Nor are they nation-state targets. But, they don’t need to run a nation-state air defense network to learn from this. CISOs should treat this as a case study in resilience under ambiguity. The question you need to answer is not “was it cyber?”, consider these:
Degraded-mode continuity – can you run operations safely when core systems are unstable and/or unreliable?
Decision advantage – can you separate signal from noise when dashboards lie and rumors spread fast?
Time-to-control – how quickly can you re-establish trusted communications, trusted identity, and trusted telemetry?
Degraded-mode operations (not just incident response)
Write, and rehearse, how the business runs when you lose one or more of the following: cloud control plane access, identity provider availability, network visibility, corporate communications, or power at a critical location. The key is to rehearse under chaos conditions to closely simulate reality. Incident Response (IR) focuses on finding, containing, eradicating, and recovering from an adversary; degraded-mode operations focus on continuing the business safely when critical systems are untrusted or unavailable, even while IR is still running.
Document manual fallbacks for critical workflows (financial transactions, customer support, OT safety, payroll).
Pre-authorize “safe shutdown” criteria for OT/ICS and safety-critical operations.
Keep offline copies of runbooks, contact trees, and key network diagrams. These need to be available in the face of communication failures.
Hunt for quiet intrusion signals in identity telemetry (e.g., leaked session objects, new OAuth app consents, unusual token grants, anomalous administrative role assignments).
Design for IdP failure (e.g., local admin recovery, limited-function authentication, and documented manual approvals).
Validate telemetry integrity, not just intrusion
In blended operations, you can lose trust in dashboards before you lose systems. Disinformation is a very real issue and its impacts can be traced way back in time. Add controls and drills that detect seemingly “false normal.”
Cross-check critical sensors (EDR vs. network telemetry vs. cloud logs) and alert on anomalies intelligently. This assumes solid baselines and visibility where it matters.
Protect logging pipelines and time synchronization, treat them as Tier-0 or critical infrastructure.
Practice operating with partial visibility, chaos, and pre-defined decision thresholds.
Prepare for communication disruption and narrative pressure
Stand up out-of-band comms (phone directories, secure messaging, satellite options for critical leaders).
Pre-stage “first 30/60 minutes” messaging for employees, customers, and regulators.
Run communications war-games that include synthetic content, deepfake audio/video, and forged internal memos.
The transferable IW lesson is: in a modern crisis, cyber won’t arrive as a separate incident, it will arrive as one layer in a blended campaign. Attackers will not separate cyber incidents from business disruption.
Key executive takeaways
Treat disruption as “effects” – rehearse crisis leadership decisions regularly, to include business decisions in order to reduce downtime exposure.
Build degraded-mode operations – drill quarterly with operational leaders in order to protect revenue continuity.
Harden identity pathways – review privileges monthly so as to cut breach-driven operational disruption.
Validate telemetry integrity – test sensors regularly to prevent false-normal blind spots.
Govern narrative risk – run communications war-games at regular intervals so as to limit reputational and market fallout.
On December 11, 2025, I spoke at the AI Summit in New York City on a topic that is becoming unavoidable for every security leader: AI is not just improving cyber attacks, it is transforming cybercrime into an intelligence discipline. Adversarial Intelligence: How AI Powers the Next Wave of Cybercrime.
The premise of the talk was simple: adversaries are no longer running isolated campaigns with a clear beginning and end. They are building living, learning models of target organizations (e.g., your people, workflows, identity fabric, operational rhythms) and then using generative-class models and autonomous agents to probe, personalize, adapt, and persist.
The core shift: AI gives attackers decision advantage
In an AI-accelerated threat environment, the attacker’s edge often comes down to decision advantage. They see you earlier, target you more precisely, and adapt in real time when controls block them. In a pre-AI world, that level of precision required time and rare talent. Now it is becoming repeatable, automated, scalable, and accessible to people with no real skill.
Where AI shows up in the modern attack lifecycle
When people think about “AI in cybercrime”, they often jump straight to malware generation. That is not wrong, but it is incomplete. In practice, AI technologies are being applied across the attack lifecycle.
Reconnaissance becomes continuous
Autonomous agents can enumerate exposed assets, map third-party relationships, and monitor public signals that reveal how teams operate. Recon becomes less like a phase and more like a background process, always learning and always refreshing the target model.
Social engineering becomes high-context
Generative models do not just write better phishing emails. They enable sentiment analysis, tone and context matching, multi-step pretexting, and persuasion that mirrors internal language and business cadence. The outcome is fewer “obvious” lures and more synthetic conversations that simply feel real.
Identity attacks scale faster than traditional controls
Identity is the front door to modern enterprises (e.g., SaaS, SSO, MFA workflows, help desk interactions, API keys). AI-powered adversaries can probe identity systems at scale, adapt-ably test variants, and blend into normal traffic patterns, especially when enforcement is inconsistent.
Deepfakes and impersonation have moved from novelty to operational enablement. They can be used for vibe hacking (e.g., pressure targets, accelerate trust, push high-risk decisions), especially in finance, vendor-payment, and administrative workflows.
The defensive answer is not “more AI“. It is better strategy.
A common trap is thinking, “attackers are using AI, so we need AI too”. Yes some AI is necessary, but alone it is not enough. Winning here requires adversary-informed security: security designed to shape attacker behavior, increase attacker cost, and force outcomes.
Three tactics that disrupt malicious automation
Deception Engineering: make the attacker waste time … on purpose
Deception is no longer just honeypots and honeytokens. Done well, it is environment design: believable paths that look like privilege or data access, instrumented to capture telemetry and shaped to slow, misdirect, and segment adversary activity. The goal is not only detection. It is decision disruption, raising uncertainty and forcing changes within the adversary’s ecosystem.
Adversarial Counterintelligence: treat your enterprise as contested information space
Assume adversaries are collecting, correlating, and modeling your ecosystem, then design against that reality. Practical counterintelligence includes reducing open-source signal leakage, hardening executive and finance workflows against impersonation, and introducing verification into high-risk decisions without paralyzing the business.
AI honeypots and canary systems: fight automation with instrumented ambiguity
AI-enabled adversaries love clean feedback loops. So do not give them any. Modern deception systems can present plausible but fake assets (APIs, credentials, source code repositories, data stores), generate dynamic content, and create unique fingerprints per interaction so automation becomes a liability.
What this means for CISOs: measure money, not security activity
If you are briefing a board, do not frame this as anything like “AI is scary”. Frame it as: AI changes loss-event frequency, loss magnitude, and time-to-detection/time-to-containment. These can directly impact revenue, downtime, regulatory exposure, and brand trust. If attackers can industrialize reconnaissance and/or persuasion, then defenders must industrialize identity visibility, verification controls, detection-to-decision workflows, and deception at scale.
Key takeaways
Assume continuous and automated recon.
Harden verification workflows against synthetic content; train executive and administrative teams regularly.
Deploy deception at scale; raise attacker cost to reduce downtime.
Operationalize counterintelligence; aim to avoid blind spots to reduce exposure.
Quantify decision advantage to accelerate funding decisions and defend revenue/margins.
Closing thought
AI is accelerating the adversary, no question. It has also lowered the entry barrier to cybercrime. But it is also giving defenders a chance to re-architect advantage: to move from passive defense to active disruption, from generic controls to adversary-shaped environments, and from security activity to measurable business outcomes.
The real message behind adversarial intelligence is this: the winners will not be the organizations that merely “adopt AI”. They will be the organizations that use it to deny attackers decision advantage, and can in turn prove it with metrics the business understands and values.
2026 is going to be a strange year in cybersecurity. Not only will it be more of the same, but bigger and louder. It stands to bring about a structural shift in who is attacking us, what we are defending, exactly where we are defending, and hopefully, who will be held accountable when things go wrong. Cybersecurity predictions for 2026: Trends to Prepare for Now.
For context, I am framing these predictions based on the way I run security and the way I find it effective to talk to board members. This is through the lens of business impact, informed by things like the adversarial mindset, identity risk, and threat intelligence.
Artificial adversaries move from Proof-of-Concept (PoC) to daily reality
In 2026, most mature organizations will start treating artificial adversaries as a normal part of their threat model. I use artificial adversaries to mean two things:
Artificial Intelligence (AI) enhanced human actors using agents, LLMs, world models, and spatial intelligence to scale their campaigns while making them far more strategic and surgically precise.
Autonomous nefarious AI that can discover, plan, and execute parts of the intrusion loop with minimal human steering. This is true end-to-end operationalized AI.
AI use will move beyond drafting convincing phishing emails to running entire playbooks end to end. These playbooks will include reconnaissance, targeting, initial access, lateral movement, exfiltration, and extortion. Campaigns will use sentiment analysis to adjust tactics and lures in real time. They will dynamically scale infrastructure and tune timing based on live target feedback, not human shift schedules.
The practical reality for defenders is simple – assume continuous, machine‑speed contact with the adversary. Design controls, monitoring, and incident response for a world where attackers never sleep. Assume they constantly learn and adapt, grow smarter as attacks progress, and never get bored. When attackers move at machine speed, identity becomes the most efficient blast radius to exploit.
Identity becomes the primary blast radius – and ITDR grows up
We have said for years that identity is the new perimeter. In 2026, identity becomes the primary blast radius. Many compromises will still start with leaked/stolen credentials, session replays, or abuse of machine and/or service identities.
Identity Threat Detection and Response (ITDR) will mature from a niche add‑on into a core capability. Identity risk intelligence will fuse signals from breach data, infostealer logs, and dark-web data into a continuous identity risk score for every user, device, service account, and, more and more, every AI agent. Enterprises will also fuse corporate identities with personal identities so the intelligence reflects a holistic risk posture.
The key question will shift from “Who are you?” to “How dangerous are you to my organization right now?” Organizations will evaluate every login and API call against current exposure, behavior, and privilege. Leaders that cannot quantify identity risk will struggle to justify their budgets because they will not be able to fight on the right battlefields.
CTEM finally becomes a decision engine, not a useless framework
Continuous Threat Exposure Management (CTEM) has been marketed heavily. In 2026 we will separate PowerPoint and analyst hype CTEM from operational CTEM. At its core, CTEM is exposure accounting, or a continuous view of what can actually hurt the business and how badly
Effective security programs will treat CTEM as continuous exposure accounting tied to revenue and regulatory risk. They will not treat CTEM as a glorified vulnerability list that never gets addressed. Exposure views will integrate identity risk, SaaS sprawl, AI agent behavior, and data ingress and egress flows. They will also include third-party dependencies in a single, adversary-aware picture.
CTEM will feed capital allocation, board reporting, and roadmap planning. If your CTEM implementation doesn’t guide where the next protective dollar goes, it isn’t CTEM. It’s just another dashboard full of metrics that a business audience can’t use. Regulators won’t care about your dashboards; they’ll care whether your CTEM program measurably reduces real-world exposure.
Regulation makes secure‑by‑design non‑negotiable (especially in the European Union (EU))
2026 is the year some regulators stop talking and start enforcing. The EU Cyber Resilience Act (CRA) moves from theory to operational reality, forcing manufacturers and software vendors targeting the EU to maintain Software Bill of Materials (SBOMs), run continuous vulnerability management, and report exploitable flaws within tight timelines. One key point here is that this is EU wide, not sector centric or targeting only publicly traded companies.
While the EU pushes toward horizontal, cross-sector obligations, the United States (U.S.) will continue to operate under a patchwork of sectoral rules and disclosure-focused expectations. SEC cyber-disclosure rules and state-level privacy laws will create pressure, but not the same unified secure-by-design mandate that CRA represents. The U.K., Singapore, Australia, and other regions will keep blending operational resilience expectations with emerging cyber and AI guidance. Global firms will then carry those standards across borders, effectively exporting them worldwide.
The EU AI Act will add another layer of pressure, particularly for vendors building or deploying high-risk AI systems. Risk management, data governance, transparency, and human oversight requirements will collide with the push to ship AI-enabled products fast. For security leaders, this means treating AI governance as part of product security, not just an ethics or compliance checkbox. You will need evidence that AI-driven features do not create unbounded security and privacy risk. Moreover, you will need to be able to explain and defend those systems to regulators.
NIS2 will also bite in practice as the first real audits and enforcement actions materialize. At the same time, capital‑markets regulators such as the SEC in the U.S. will continue to scrutinize cyber disclosures and talk about board‑level oversight of cybersecurity risk.
There is a net effect here – cybersecurity becomes a product-safety and market-access problem. If your product cannot stand up to CRA-grade expectations, AI-governance scrutiny, and capital-markets disclosure rules, you will lose market share or access. Some executives will discover that cyber failures now have grand, and potentially personal, consequences.
Disinformation, deepfakes, and synthetic extortion professionalize and achieve scale
We are already seeing AI‑generated extortion and executive impersonations. In 2026, these will become industrialized. Adversaries will mass‑produce tailored deepfake incidents against executives, employees, and customers. Fake scandal footage and spoofed “CEO-in-crisis” voice calls ordering urgent payments will hit at scale. The surge will mirror how the NPD sextortion wave spread in 2024.
Digital trust has eroded to a disturbing point. Brand and executive reputation will be treated as high‑value assets in this new threat landscape. Attackers will try to weaponize misinformation not only to manipulate politics and financial markets, but also to further break trust in areas such as incident‑response communications and official statements.
This is where vibe hacking becomes mainstream as the next generation of social engineering. Campaigns will focus less on factual deception and more on psychological, emotional, and social manipulation. They will create exploitable chaos across individuals’ lives and inside organizations and societies.
The software supply chain gets regulated, measured, and attacked at the same time
In 2026, the software supply‑chain story gets more complex, not less. Regulatory SBOM requirements are ramping up at the same time that organizations add more SaaS, more APIs, more AI tooling, and more automation platforms.
Adversaries will continue to target upstream build systems, AI models, plugins, and shared components because compromising one dependency scales beautifully across many downstream organizations.
Educated boards will shift from asking, “Do we have an SBOM?” to asking sharper questions. They will ask, “How fast can we detect a poisoned component and isolate the blast radius?” They will also ask how we can prove containment to regulators and customers. Continuous, adversary-aware supply-chain monitoring will replace static, point-in-time attestations.
Deception engineering and security chaos engineering become standard practice
Static and traditional defenses are proving to age badly against autonomous and AI‑enhanced adversaries. In 2026 we will see sophisticated programs move toward deception engineering at scale (e.g., documents with canary tokens, deceptive credentials, honeypot workloads, decoy SaaS instances, and fake data pipelines) instrumented to deceive attackers and capture their behavior. Deception engineering techniques will become powerful tools to force AI‑powered attackers to burn resources.
Sophisticated programs will also start to leverage Security Chaos Engineering (SCE) as part of their standard practices. They will expand SCE exercises from infrastructure into identity and data paths. Teams will deliberately inject failures and simulated attacks into IAM, SSO, PAM, and data flows to measure real‑world resilience rather than relying on configuration checklists and Table Top Exercises (TTX).
AI browsers and memory‑rich clients become a new battleground
AI‑augmented browsers and workspaces are getting pushed on to users fast. They promise enormous productivity boosts by providing long‑term memory, cross‑tab reasoning, and deep integration into enterprise data. They also represent a new, high-value target for attackers. Today, most of these tools are immature, but like many end-user products we may or may not need, they will still find their way into homes and enterprises.
A browser or client that remembers everything a user has read, typed, or uploaded over months is effectively a curated data‑exfiltration cache if compromised. Most organizations will adopt these tools faster than they update Data Loss Prevention (DLP) stacks, privacy policies, or access controls.
We will also see agent‑to‑agent risk. The proliferation of decentralized agentic ecosystems will see to this. Inter-agent communication is both a feature of adaptability and a new element in attack surfaces. Authentication, authorization, and auditing of these machine‑to‑machine conversations will lag behind adoption unless CISOs force the issue and tech teams play some serious catch up.
Cyber-physical incidents force boards to treat Operational Technology (OT) risk as P&L risk
In 2026, leaders will stop treating cyber-physical incidents as IT edge cases and discuss them in P&L reviews. Human and artificial adversaries will learn OT protocols and process flows, not just IT systems. They will increasingly target manufacturing lines, logistics hubs, energy assets, and healthcare infrastructure. AI-enhanced reconnaissance and simulation will let attackers model physical impact before they strike. They will design campaigns that maximize downtime, safety risk, and disruption with minimal effort. This shift will move board discussions beyond breaches and ransomware to operational outages and safety-adjacent events. Boards will no longer dismiss these incidents as purely IT problems.
This dynamic will push organizations to bring OT and ICS security into mainstream risk management. Teams will quantify OT exposure using the same terms as other strategic risks. They will measure impact on revenue continuity, contractual SLAs, supply-chain reliability, and regulatory exposure. CTEM programs that only cover web apps, APIs, and cloud assets will look dangerously incomplete. A single compromised PLC or building management system can halt production or shut down an entire facility. Boards will expect cyber-physical scenarios to show up in resilience testing, TTXs, and stress tests.
The organizations that are mature and handle this well will build joint playbooks between security, operations, and finance. They will treat OT risk as part of protected ARR, and fund segmented architectures, OT-aware monitoring, and incident drills before something breaks. Those that treat OT as “someone else’s problem” will discover in the worst possible way that cyber-physical events don’t just hit uptime metrics, they threaten revenue and safety in ways that no insurance or PR campaign can fully repair.
Boards will demand money metrics, not motion metrics
Economic pressure and regulatory exposure will push educated board members away from vanity metrics like counts of alerts, vulnerabilities, or training completions. Instead, they will demand money metrics, such as – “how much ARR is truly protected”, “how much is revenue is exposed to specific failures”, and what it costs to defend an event or buy down a risk.
As AI drives both attack and defense costs, boards will expect clear security ROI curves. It will need to clear where additional investment materially reduces expected loss and where it simply feeds some useless dashboard.
CISOs who cannot fluently connect technical initiatives to capital allocation, risk buy‑down, and protected revenue will be sidelined in favor of leaders who can.
Talent, operating models, and playbooks reorganize around AI
Tier‑1 analyst work will be heavily automated by 2026. AI copilots and agents will handle first‑line triage, basic investigations, and routine containment for common issues. Human talent will move up‑stack toward adversary and threat modeling, complex investigations, and business alignment.
The more forward thinking CISOs will push for new roles such as:
Adversarial‑AI engineers focused on testing, hardening, and red‑teaming AI systems
Identity‑risk engineers owning the integration of identity risk intelligence, ITDR, and IAM
Deception and chaos engineers responsible for orchestrating real resilience tests and deceptive environments
Incident Response (IR) playbooks will evolve from static, linear documents into adaptable orchestrations of defensive and likely distributed agents. The CISO’s job will start to shift towards designing and governing a cyber‑socio‑technical system where humans and machines defend together. This will require true vision, innovation, and a different mindset than what has brought our industry to current state.
Cyber insurance markets raise the bar and price in AI-driven risk
In 2026, cyber insurance will no longer be treated as a cheap safety net that magically transfers away existential risk. As AI-empowered adversaries drive both the scale and correlation of loss events, carriers will respond the only way they can – by tightening terms, raising premiums, and narrowing what is actually covered. We will see more exclusions for “systemic” or “catastrophic” scenarios and sharper scrutiny on whether a given loss is truly insurable versus a failure of basic governance and control.
Underwriting will also likely mature from checkbox questionnaires to evidence-based expectations. Insurers will increasingly demand proof of things like a functioning CTEM program, identity-centric access controls, robust backup and recovery, and operational incident readiness before offering meaningful coverage at acceptable pricing. In other words, the quality of your exposure accounting and control posture will directly affect not only whether you can get coverage, but at what price and with what limits and deductibles. CISOs who can show how investments in CTEM, identity, and resilience reduce expected loss will earn real influence over the risk-transfer conversation.
Boards will in turn be forced to rethink cyber insurance as one lever in a broader risk-financing strategy, not a substitute for security. The organizations that win here will be those that treat insurance as a complement to disciplined exposure reduction. Everyone else will discover that in an era of artificial adversaries and correlated failures, you cannot simply insure your way out of structural cyber risk.
Cybersecurity product landscape – frameworks vs point solutions
The product side of cybersecurity will go through a similar consolidation and bifurcation. The old debate of platform versus best‑of‑breed is evolving into a more nuanced reality, one based on a small number of control‑plane frameworks surrounded by a sharp ecosystem of highly specialized point solutions.
Frameworks will naturally attract most of a CISOs budget. Buyers, boards, and CFOs are tired of stitching together dozens of tools that each solve a sliver of a much larger set of problems. They want a coherent architecture with fewer strategic vendors that can provide unified accountability, prove coverage, reduce operational load, and expose clean APIs for integration with those highly specialized point solutions.
However, this does not mean the death of point solutions. It means the death of shallow, undifferentiated point products. The point solutions that survive will share three traits:
They own or generate unique signal or data
They solve a unique, hard, well‑bounded problem extremely well
They integrate cleanly into the dominant frameworks instead of trying to replace them
Concrete examples of specialization include effective detection of synthetic identities, high‑fidelity identity risk intelligence powered by large data lakes, deep SaaS and API discovery engines, vertical‑specific OT/ICS protections, and specialized AI‑security controls for model governance, prompt abuse, and training‑data risk. These tools win when they become the intelligence feed or precision instrument that makes a framework materially smarter.
For buyers, there is a clear pattern – design your mesh architecture around a spine of three to five control planes (e.g., identity, data, cloud, endpoint, and detection/response) and treat everything else as interchangeable modules. For vendors, the message is equally clear – be the mesh/framework, be the spine, or be the sharp edge. The mushy middle will not survive 2026.
Executive key takeaways
Treat AI‑powered adversaries as the default case, not an edge case.
Fund CTEM as an operational component.
Fund deception, chaos engineering, and adaptable IR to minimize dwell time and downtime.
Focus on protecting revenue and being able to prove it.
Put identity at the center of both your cyber mesh and balance sheet.
Align early with CRA, NIS2, and/or AI governance. Trust attestations and external proof of maturity carry business weight. Treat SBOMs, exposure reporting, and secure‑by‑design as product‑safety controls, not IT projects.
Invest in truth, provenance, and reputation defenses. Prepare for deepfake‑driven extortion en-masse and disinformation that can shift markets in short periods of time.
Rebuild metrics, products, and talent around business impact. Choose frameworks both subjectively and strategically, and then plug in sharp point solutions where they really have a positive impact on risk.
Organizational leaders must manage risk and have to factor in various areas of risk. Cybersecurity risk has risen to a ranking worthy of the attention of business leaders, generally speaking the C-Suite and members of the Board of Directors (BoD). Chief Information Security Officers (CISOs) and their teams are responsible for informing said business leadership about cybersecurity risk to the organization at hand. All of that is basic knowledge at this stage. CISOs need to focus on profit signals, not security static.
This seems like a relatively simple relationship with two sides to it. One one side there are those business leaders. On the other are cybersecurity leaders. Both sides are concerned with risk. But both sides don’t focus on, and interpret, risk the same way. This is where the situation is no longer basic.
The Situation
For a given area of risk, CISOs often analyze the type and try to figure out ways to manage that area of risk. The type and severity matter and they build platforms and risk registers to perform functions such as organizing the relevant data and exercising prioritization on that data. The focus however is generally on the risk itself, in the abstract.
Most business leaders don’t care about risk in the abstract. They care about the financial impact if some risk gets actualized (if it actually happens). Their concern is impact by way of these types of questions:
How much Annual Recurring Revenue (ARR) is at stake?
How will a severe event impact the company’s cash?
What does this risk mean for Earnings Before Interest, Taxes, Depreciation, and Amortization (EBITDA)?
Traditional cybersecurity metrics like vulnerability management statistics, Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR) describe activity, not business outcomes. CISOs must shift the conversation to be recognized as business leaders. For example, quantify how security protects revenue continuity. Show how security accelerates growth, preserves liquidity, and improves margins.
There are no formulas in terms of what metrics will resonate with a particular business leader, or group of leaders. Ultimately, the best metrics are those which make sense, and add value, to a specific audience. Given that, the following example metrics are provided in good faith and intended to inspire thought in this arena. They are designed for revenue-centric cybersecurity leaders in order to generate interest with business leaders. Each example comes with a clear definition, sections like ‘why it matters’ and ‘how to compute’, and practical examples.
Metrics Examples
These examples are grouped by business outcomes:
Revenue Continuity
Cash and Liquidity
Growth Velocity
Margin
Percentiles primer:
p50 is the median of the actual loss distribution. This means there is a 50% probability that the actual loss will be greater than the p50 value and a 50% probability that it will be lower.
p95, or the 95th percentile, is a statistical measure indicating that 95% of a set of values are less than or equal to that specific value. The remaining 5% will be higher.
Revenue Continuity
This area focuses on keeping booked revenue deliverable and renewable despite security friction. Emphasize leading indicators such as the reliability of verified recovery processes. Trend typical performance and worst-case exposure so directors see both the steady state and the possibilities if things turn negative. Define thresholds that trigger remediation or some other activity to manage risk, and make business continuity a shared objective between the CISO and Revenue/Sales Operations. For example, security teams can show what percentage of ARR their controls protect.
Protected ARR
How it is represented – percentage.
Why it matters – shows how much revenue is insulated from outages/breaches.
How to compute – (ARR delivered by systems operated within an ecosystem of strong resilience ÷ total ARR) × 100.
Strong resilience can include:
Tested Disaster Recovery (DR) to Recovery Time Objective (RTO)/Recovery Point Objective (RPO)
Subscriptions ($120M) + MFA based Platform ($40M) – pass.
Legacy app ($40M) that cannot support MFA – fails.
Protected ARR = 80% or (160/200) X 100.
In plain English – this percentage represents the share of annual recurring revenue that’s safely insulated from outages or breaches because it runs on resilient, well-governed systems.
Cash and Liquidity
This section demonstrates the organization’s ability to withstand a severe disruption without jeopardizing cash. Quantify peak cash needs under stress by modeling downtime, restoration, legal/forensic work, business interruption, and insurance deductibles/exclusions. Show both expected impact and a tail event (a low-probability, high-impact loss scenario that lives in the extreme “tail” of your risk distribution) so that leadership and/or the board understands ceilings. Pair this with quarterly tabletops and pre-approved financing levers (credit facilities, insurance endorsements, indemnities) co-owned by the CISO and CFO to avoid emergency dilution and keep liquidity intact.
Ransomware Liquidity Impact
How it is represented – dollar amount with relevant impact time frame.
Why it matters – quantifies cash impact so that cash reserves are factored into plans.
Link dollar amount to estimated impacted “days of operating expense”
Example: $13M ≈ 12 days of operating expenses.
Ransom cost – $20M.
Downtime cost – $5M.
Recovery cost – $3M.
Insurance recovery ~$15M.
Estimated net cash hit – $13M or (20 + 5 + 3) – 15.
Estimation of 12 days of operating expenses (subjective to the organization).
In plain English – this metric represents the cash you would need on hand for a severe ransomware event, expressed as a dollar amount and translated into “days of operating expense” (how many days of normal operating spend that amount equals) so you can tell if reserves are adequate.
Growth Velocity
This section revolves around trust signals and how they facilitate enterprise sales. Explain how being “procurement-ready” up front (e.g., proofs, attestations, control evidence) removes friction from security reviews, shortens sales cycles, and improves conversion. Tie readiness to deal-desk gates (no deal without required proofs), add advance alerts for expiring artifacts, and segment by region or vertical to target subjective bottlenecks. A possible addition is to report changes in deal win rates and days-to-close alongside readiness so security’s growth impact is unmistakable.
Trust Attestation Coverage
How it is represented – percentage and dollar amount tied to upcoming expirations (time bound).
Why it matters – establishes range of coverage and can unlock insights into renewals that have attached requirements. This can also identify areas where requirements are not being met.
How to compute:
(ARR requiring attestations with current reports ÷ ARR requiring attestations) × 100;
Flag expiring attestations and ARR at risk in some time bound period.
Example: 80% currently covered; $15M ARR tied to attestations expiring within 90 days.
ARR requiring attestations – $200M.
ARR covered by current attestations – $160M.
80% = (160/200) X 100.
Of the remaining $40M, $15M is tied to attestations/reports that expire within the next 90 days.
In plain English – this metric represents the share of revenue that already has the required security/compliance proofs (e.g., SOC 2, ISO 27001) in place, plus a look-ahead of dollars at risk from proofs expiring soon.
Margin
This section intends to connect strong data governance to healthier unit economics. Show coverage of sensitive records under enforceable controls and quantify residual exposure where coverage is missing. As governance coverage improves, incidents shrink, reviews streamline, and support and compliance costs fall, leading to lifts in gross margins.
Customer Data Coverage
How it is represented – percentage and dollar amount of exposure.
Why it matters – reduces breach cost (fines, legal, response) and can protect renewals, which can in turn improve EBITDA. This can also directly improve customer confidence.
How to compute:
From Data Security Posture Management (DSPM) inventory – percentage of sensitive data (e.g., Personally Identifiable Information (PII), etc) stored with native encryption in place.
Native encryption means record or column level encryption, not at a volume or disk storage level.
Uncovered records × assumed $/record for exposure modeling.
Example: 85% coverage, $37.5M exposure.
DSPM inventory (total number of records discovered) – 1,666,666.
Shows that 85% of records are covered by native encryption.
15% uncovered = ~250,000 records.
At $150.00/record (150 × 250,000) = ~$37.5M exposure.
In plain English – this metric represents the percent of sensitive records protected by native, record/column-level encryption, reported alongside a dollar estimate of what’s not protected. Higher coverage lowers breach costs, protects renewals, and boosts customer confidence.
Recommendations
Start with baselines for the current state.
Compute metrics such as Protected ARR, Ransomware Liquidity Impact, Trust Attestation Coverage, and Customer Data Coverage.
Using those baselines, set 12‑month targets.
Assign executive owners per metric with reviews at a regular cadence.
Example: CISO/Chief Finance Officer (CFO) co‑ownership for liquidity.
Integrate metrics into gates.
Block product/software launches lacking required control tests and/or attestations.
Tie Attestation Coverage to enterprise pipeline forecasting.
Flag expirations 90 days ahead with ARR at risk.
Use DSPM to uncover areas that can be addressed to create a raise in Customer Data Coverage.
Track uncovered records × $/record to quantify exposure.
Make finance your data partner.
Reconcile assumptions (credit issuance rates, loss per record, downtime cost) at regular intervals.
Incentivize security driven financial outcomes.
Push for leadership bonuses to be linked to movement in Protected ARR, reduced cash‑at‑risk, and revenue protection.
Conclusion
Cybersecurity only earns durable credibility with board members when it speaks the language of money. Shift the center of gravity from activity counts to financial outcomes. Treat things like “Protected ARR”, “Ransomware Liquidity Impact”, “Trust Attestation Coverage”, and the “Customer Data Coverage” as headline metrics. Show trends so leaders can reason about typical loss and tail risk. The result becomes a shared decision frame with your C-Level peers and/or board directors. This equates to less debate over technical minutiae, more alignment on where to invest, what to defer, and what risk to carry.
Execution is where credibility compounds for cybersecurity leadership. Assign metric owners, set board-visible thresholds, and wire these measures into operating rhythms:
Quarterly planning
Deal-desk approvals
Release gates
Disaster Recovery exercises
Renewal risk reviews.
Close every discussion with a clear “security metric leads to money” translation, for example:
Protected ARR leads to fewer credits/lost transactions.
Trust Attestation Coverage leads to faster enterprise sales or new opportunities in a pipeline.
When security is measured in dollars protected, cash preserved, and/or margin improved, it stops being a cost center and becomes an instrument of business growth. Focusing on profit signals, not security static positions a CISO to be perceived as a partner by business leaders.
In an age where cyber attackers have become more intelligent, agile, persistent, sophisticated, and empowered by Artificial Intelligence (AI), defenders must go beyond traditional detection and prevention. The traditional models of protective security are fast becoming diminished in their effectiveness and power. In the face of pursuing a proactive model one approach has emerged, security chaos engineering. It offers a proactive strategy that doesn’t just lead to hardened systems but can also actively disrupt and deceive attackers during their nefarious operations. How security chaos engineering disrupts adversaries in real time.
By intentionally injecting controlled failures or disinformation into production-like environments, defenders can observe attacker behavior, test the resilience of security controls, and frustrate adversarial campaigns in real time.
Two of the most important frameworks shaping modern cyber defense are MITRE ATT&CK (https://attack.mitre.org/) and MITRE Engage (https://engage.mitre.org/). Together, they provide defenders with a common language for understanding adversary tactics and a practical roadmap for implementing active defense strategies. This can transform intelligence about attacker behavior into actionable, measurable security outcomes. The convergence of these frameworks with security chaos engineering adds some valuable structure when building actionable and measurable programs.
What is MITRE ATT&CK?
MITRE ATT&CK (Adversarial Tactics, Techniques, and Common Knowledge) is an open, globally adopted framework developed by MITRE (https://www.mitre.org/) to systematically catalog and describe the observable tactics and techniques used by cyber adversaries. The ATT&CK matrix provides a detailed map of real-world attacker behaviors throughout the lifecycle of an intrusion, empowering defenders to identify, detect, and mitigate threats more effectively. By aligning security controls, threat hunting, and incident response to ATT&CK’s structured taxonomy, organizations can close defensive gaps, benchmark their capabilities, and respond proactively to the latest adversary tactics.
What is MITRE Engage?
MITRE Engage is a next-generation knowledge base and planning framework focused on adversary engagement, deception, and active defense. Building upon concepts from MITRE Shield, Engage provides structured guidance, practical playbooks, and real-world examples to help defenders go beyond detection. These data points enable defenders to actively disrupt, mislead, and study adversaries. Engage empowers security teams to plan, implement, and measure deception operations using proven techniques such as decoys, disinformation, and dynamic environmental changes. This bridges the gap between understanding attacker Techniques, Tactics, and Procedures (TTPs) and taking deliberate actions to shape, slow, or frustrate adversary campaigns.
What is Security Chaos Engineering?
Security chaos engineering is the disciplined practice of simulating security failures and adversarial conditions in running production environments to uncover vulnerabilities and test resilience before adversaries can. Its value lies in the fact that it is truly the closest thing to a real incident. Table Top Exercises (TTXs) and penetration tests always have constraints and/or rules of engagement which distance them from real world attacker scenarios where there are no constraints. Security chaos engineering extends the principles of chaos engineering, popularized by Netflix (https://netflixtechblog.com/chaos-engineering-upgraded-878d341f15fa) to the security domain.
Instead of waiting for real attacks to reveal flaws, defenders can use automation to introduce “security chaos experiments” (e.g. shutting down servers from active pools, disabling detection rules, injecting fake credentials, modifying DNS behavior) to understand how systems and teams respond under pressure.
The Real-World Value of this Convergence
When paired with security chaos engineering, the combined use of ATT&CK and Engage opens up a new level of proactive, resilient cyber defense strategy. ATT&CK gives defenders a comprehensive map of real-world adversary behaviors, empowering teams to identify detection gaps and simulate realistic attacker TTPs during chaos engineering experiments. MITRE Engage extends this by transforming that threat intelligence into actionable deception and active defense practices, in essence providing structured playbooks for engaging, disrupting, and misdirecting adversaries. By leveraging both frameworks within a security chaos engineering program, organizations not only validate their detection and response capabilities under real attack conditions, but also test and mature their ability to deceive, delay, and study adversaries in production-like environments. This fusion shifts defenders from reactive posture to one of continuous learning and adaptive control, turning every attack simulation into an opportunity for operational hardening and adversary engagement.
Here are some security chaos engineering techniques to consider as this becomes part of a proactive cybersecurity strategy:
Temporal Deception – Manipulating Time to Confuse Adversaries
Temporal deception involves distorting how adversaries perceive time in a system (e.g. injecting false timestamps, delaying responses, or introducing inconsistent event sequences). By disrupting an attacker’s perception of time, defenders can introduce doubt and delay operations.
Example: Temporal Deception through Delayed Credential Validation in Deception Environments
Consider a deception-rich enterprise network, temporal deception can be implemented by intentionally delaying credential validation responses on honeypot systems. For instance, when an attacker attempts to use harvested credentials to authenticate against a decoy Active Directory (AD) service or an exposed RDP server designed as a trap, the system introduces variable delays in login response times, irrespective of the result (e.g. success, failure). These delays mimic either overloaded systems or network congestion, disrupting an attacker’s internal timing model of the environment. This is particularly effective when attackers use automated tooling that depends on timing signals (e.g. Kerberos brute-forcing or timing-based account validation). It can also randomly slow down automated processes that an attacker hopes completes within some time frame.
By altering expected response intervals, defenders can inject doubt about the reliability of activities such as reconnaissance and credential validity. Furthermore, the delayed responses provide defenders with crucial dwell time for detection and the tracking of lateral movement. This subtle manipulation of time not only frustrates attackers but also forces them to second-guess whether their tools are functioning correctly or if they’ve stumbled into a monitored and/or deceptive environment.
As an example of some of the ATT&CK TTPs and Engage mappings that can be used when modeling this example of temporal deception, the following support the desired defensive disruption:
MITRE ATT&CK Mapping
T1110 – Brute Force – many brute force tools rely on timing-based validation. By introducing delays, defenders interfere with the attacker’s success rate and timing models.
T1556 – Modify Authentication Process – typically this is seen as an adversary tactic. But defenders can also leverage this by modifying authentication behavior in decoy environments to manipulate attacker perception.
T1078 – Valid Accounts – delaying responses to login attempts involving potentially compromised credentials can delay attacker progression and reveal account usage patterns.
MITRE Engage Mapping
Elicit > Reassure > Artifact Diversity – deploying decoy credentials or artifacts to create a convincing and varied environment for the adversary. Temporal manipulation of login attempts involving decoy credentials helps track adversary interactions and delay their movement.
Elicit > Reassure > Burn-In – introducing friction, delays, or noise to slow down or frustrate automated attacker activities.
Affect > Disrupt > Software Manipulation – modifying system or application software to alter attacker experience, disrupt automation, or degrade malicious tooling. Introducing time delays and inconsistent system responses create false environmental cues, leading attackers to make incorrect decisions. Also introducing artificial latency into authentication routines or system responses slows down the attack lifecycle and adds noise to attacker automation.
Affect > Disrupt | Direct > Network Manipulation – changing or interfering with network traffic, services, or routing to disrupt attacker operations. Also influencing or steering attacker decision-making and movement in the environment.
Affect > Disrupt > Isolation – segregating attacker interactions or dynamically altering access to increase confusion and contain threats.
Expose > Detect > Lures | Network Analysis – observing, logging, and analyzing adversary actions for intelligence and response purposes.
Expose > Collect > API Monitoring | Network Monitoring | System Activity Monitoring – extended interaction windows (due to delayed responses) give defenders more opportunity to monitor adversary behavior within the decoy environment.
Honey Timing and Time-Based Traps
Time-bound honeypots such as fake cron jobs, scheduled updates, or bogus backup routines can serve as deceptive traps. Interaction with these elements reveals unauthorized probing or access attempts. The very existence of these traps implies that any entity interacting with them (excluding the creators of course) needs to be treated as hostile and investigated.
Example: Deceptive Backup Scripts as Time-Based Traps in Cloud Environments
Defenders can deploy a bogus scheduled backup script named “nightly-db-backup.sh” on a decoy cloud instance. The script can be set to appear as if it ran daily at 04:00 using a convincingly sounding cron job (e.g. /etc/cron.d/backup_job). The script can contain clear-text references to fake database credentials, S3 storage paths, and mock sensitive data exports. This can be used as a timing-based honeypot, existing to attract unauthorized access attempts during off-hours when legitimate activity is minimal.
Any attempt to execute this script triggers hidden canary tokens that act as an alerting system. This can trigger things like an HTTP request where the receiving entity (e.g. web server processing the request) has been configured to log and alert on any relevant interaction. This can of course capture timestamps showing interactions with the script outside of the bogus scheduled execution window. The defenders can then not only detect the unauthorized access but also track subsequent movements due to some of the meta-data captured.
This approach demonstrates how time-based decoy elements, especially those aligned with off-hour routines, can effectively expose stealthy adversaries who are mimicking typical system administrator behavior.
As an example of some of the ATT&CK TTPs and Engage mappings that can be used when modeling this example of time based decoys, the following support the desired defensive disruption:
MITRE ATT&CK Mapping
T1059 – Command and Scripting Interpreter – the attacker manually executes some script using bash or another shell interpreter.
T1083 – File and Directory Discovery – the attacker browses system files and cron directories to identify valuable scripts.
T1070.004 – Indicator Removal: File Deletion – often attackers attempt to clean up after interacting with trap files.
T1562.001 – Impair Defenses: Disable or Modify Tools – attempting to disable cron monitoring or logging after detection is common.
MITRE Engage Mapping
Elicit > Reassure > Artifact Diversity – deploying decoy credentials or artifacts to create a convincing and varied environment for the adversary.
Affect > Disrupt > Software Manipulation – modifying system or application software to alter attacker experience, disrupt automation, or degrade malicious tooling.
Affect > Disrupt > Isolation – segregating attacker interactions or dynamically altering access to increase confusion and contain threats.
Expose > Detect > Lures – observing, logging, and analyzing adversary actions for intelligence and response purposes.
Randomized Friction
Randomized friction aims at increasing an attacker’s work factor, in turn increasing the operational cost for the adversary. Introducing unpredictability in system responses (e.g. intermittent latency, randomized errors, inconsistent firewall behavior) forces attackers to adapt continually, degrading their efficiency and increasing the likelihood of detection.
Example: Randomized Edge Behavior in Cloud Perimeter Defense
Imagine a blue/red team exercise within a large cloud-native enterprise. The security team deploys randomized friction techniques on a network segment believed to be under passive recon by red team actors. The strategy can include intermittent firewall rule randomization. Some of these rules make it so that attempts to reach specific HTTP based resources are met with occasional timeouts, 403 errors, misdirected HTTP redirects, or to simply give an actual response.
When the red team conducts external reconnaissance and tries to enumerate target resources, they experience inconsistent results. One of their obvious objectives is to remain undetected. Some ports appeared filtered one moment and opened the next. API responses switch between errors, basic authentication challenges, or other missing element challenges (e.g. HTTP request header missing). This forces red team actors to waste time revalidating findings, rewriting tooling, and second-guessing whether their scans were flawed or if detection had occurred.
Crucially, during this period, defenders are capturing every probe and fingerprint attempt. The friction-induced inefficiencies increase attack dwell time and volume of telemetry, making detection and attribution easier. Eventually, frustrated by the lack of consistent telemetry, the red team escalates their approach. This kills their attempts at stealthiness and triggers active detection systems.
This experiment successfully degrades attacker efficiency, increases their operational cost, and expands the defenders’ opportunity window for early detection and response, all without disrupting legitimate internal operations. While it does take effort on the defending side to set all of this up, the outcome would be well worth it.
As an example of some of the ATT&CK TTPs and Engage mappings that can be used when modeling this example of randomized friction, the following support the desired defensive disruption:
MITRE ATT&CK Mapping
T1595 – Active Scanning – adversaries conducting external enumeration are directly impacted by inconsistent firewall responses.
T1046 – Network Service Discovery – random port behavior disrupts service mapping efforts by the attacker.
T1583.006 – Acquire Infrastructure: Web Services – attackers using disposable cloud infrastructure for scanning may burn more resources due to retries and inefficiencies.
MITRE Engage Mapping
Elicit > Reassure > Artifact Diversity – deploying decoy credentials or artifacts to create a convincing and varied environment for the adversary.
Elicit > Reassure > Burn-In – introducing friction, delays, or noise to slow down or frustrate automated attacker activities.
Affect > Disrupt > Software Manipulation – modifying system or application software to alter attacker experience, disrupt automation, or degrade malicious tooling.
Affect > Disrupt > Network Manipulation – changing or interfering with network traffic, services, or routing to disrupt attacker operations.
Affect > Disrupt > Isolation – segregating attacker interactions or dynamically altering access to increase confusion and contain threats.
Expose > Detect > Network Analysis – observing, logging, and analyzing adversary actions for intelligence and response purposes.
Ambiguity Engineering
Ambiguity engineering aims to obscure the adversary’s mental model. It is the deliberate obfuscation of system state, architecture, and behavior. When attackers cannot build accurate models of the target environments, their actions become riskier and more error-prone. Tactics include using ephemeral resources, shifting IP addresses, inconsistent responses, and mimicking failure states.
Example: Ephemeral Infrastructure and Shifting Network States in Zero Trust Architectures
A SaaS provider operating in a zero trust environment can implement ambiguity engineering as part of its cloud perimeter defense strategy. In this setup, let’s consider a containerized ecosystem that leverages Kubernetes-based orchestration. This platform can utilize elements such as ephemeral IPs and DNS mappings, rotating them at certain intervals. These container hosted backend services would be accessible only via authenticated service mesh gateways, but appear (to external entities) to intermittently exist, fail, or timeout, depending on timing and access credentials.
Consider the external entity experience against a target such as this. These attackers would be looking for initial access followed by lateral movement and service enumeration inside this target environment. What they would encounter are API endpoints that resolve one moment and vanish the next. Port scans would deliver inconsistent results across multiple iterations. Even successful service calls can return varying error codes depending on timing and the identity of the caller. When this entity tries to correlate observed system behaviors into a coherent attack path, they would continually hit dead ends.
This environment was not broken, it was intentionally engineered for ambiguity. The ephemeral nature of resources, combined with intentional mimicry of common failure states, would prevent attackers from forming a reliable mental model of system behavior. Frustrated and misled, their attack chain will slow, errors will increase, and their risk of their detection will rise. Meanwhile, defenders can capture behavioral fingerprints from the failed attempts and gather critical telemetry for informed future threat hunting and active protection.
As an example of some of the ATT&CK TTPs and Engage mappings that can be used when modeling this example of ambiguity engineering, the following support the desired defensive disruption:
MITRE ATT&CK Mapping
T1046 – Network Service Discovery – scanning results are rendered unreliable by ephemeral network surfaces and dynamic service allocation.
T1590 – Gather Victim Network Information – environmental ambiguity disrupts adversary reconnaissance and target mapping.
T1001.003 – Data Obfuscation: Protocol or Service Impersonation – false failure states and protocol behavior can mimic broken or legacy services, confusing attackers.
MITRE Engage Mapping
Elicit > Reassure > Artifact Diversity – deploying decoy credentials or artifacts to create a convincing and varied environment for the adversary.
Elicit > Reassure > Burn-In – introducing friction, delays, or noise to slow down or frustrate automated attacker activities.
Affect > Disrupt > Software Manipulation – modifying system or application software to alter attacker experience, disrupt automation, or degrade malicious tooling.
Affect > Disrupt > Network Manipulation – changing or interfering with network traffic, services, or routing to disrupt attacker operations.
Affect > Disrupt > Isolation – segregating attacker interactions or dynamically altering access to increase confusion and contain threats.
Expose > Detect > Network Analysis – observing, logging, and analyzing adversary actions for intelligence and response purposes.
Affect > Direct > Network Manipulation – changing or interfering with network traffic, services, or routing to disrupt attacker operations.
Disinformation Campaigns and False Flag Operations
Just as nation-states use disinformation to mislead public opinion, defenders can plant false narratives within ecosystems. Examples include fake internal threat intel feeds, decoy sensitive documents, or impersonated attacker TTPs designed to confuse attribution.
False flag operations are where an environment mimics behaviors of known APTs. The goal is to get one attack group to think another group is at play within a given target environment. This can redirect adversaries’ assumptions and deceive real actors at an operational stage.
Example: False Flag TTP Implantation to Disrupt Attribution
Consider a long-term red vs. blue engagement inside a critical infrastructure simulation network. The blue team defenders implement a false flag operation by deliberately injecting decoy threat actor behavior into their environment. This can include elements such as:
Decoy documents labeled as “internal SOC escalation notes” with embedded references to Cobalt Strike Beacon callbacks allegedly originating from Eastern European IPs.
All of these artifacts can be placed in decoy systems, honeypots, and threat emulation zones designed to be probed or breached. The red team, tasked with emulating an external APT, stumble upon these elements during lateral movement and begin adjusting their operations based on the perceived threat context. They will incorrectly assume that a separate advanced threat actor is and/or was already in the environment.
This seeded disinformation can slow the red team’s operations, divert their recon priorities, and lead them to take defensive measures that burn time and resources (e.g. avoiding fake IOC indicators and misattributed persistence mechanisms). On the defense side, telemetry confirmed which indicators were accessed and how attackers reacted to the disinformation. This can become very predictive regarding what a real attack group would do. Ultimately, the defenders can control the narrative within an engagement of this sort by manipulating perception.
As an example of some of the ATT&CK TTPs and Engage mappings that can be used when modeling this example of disinformation, the following support the desired defensive disruption:
MITRE ATT&CK Mapping
T1005 – Data from Local System – adversaries collect misleading internal documents and logs during lateral movement.
T1204.002 – User Execution: Malicious File – decoy files mimicking malware behavior or containing false IOCs can trigger adversary toolchains or analysis pipelines.
T1070.001 – Indicator Removal: Clear Windows Event Logs – adversaries may attempt to clean up logs that include misleading breadcrumbs, thereby reinforcing the deception.
MITRE Engage Mapping
Elicit > Reassure > Artifact Diversity – deploying decoy credentials or artifacts to create a convincing and varied environment for the adversary.
Elicit > Reassure > Burn-In – introducing friction, delays, or noise to slow down or frustrate automated attacker activities.
Affect > Disrupt > Software Manipulation – modifying system or application software to alter attacker experience, disrupt automation, or degrade malicious tooling.
Affect > Disrupt > Network Manipulation – changing or interfering with network traffic, services, or routing to disrupt attacker operations.
Affect > Disrupt > Isolation – segregating attacker interactions or dynamically altering access to increase confusion and contain threats.
Affect > Direct > Network Manipulation – changing or interfering with network traffic, services, or routing to disrupt attacker operations.
Expose > Detect > Network Analysis – observing, logging, and analyzing adversary actions for intelligence and response purposes.
Real-World Examples of Security Chaos Engineering
One of the most compelling real-world examples of this chaos based approach comes from UnitedHealth Group (UHG). As one of the largest healthcare enterprises in the United States, UHG faced the dual challenge of maintaining critical infrastructure uptime while ensuring robust cyber defense. Rather than relying solely on traditional security audits or simulations, UHG pioneered the use of chaos engineering for security.
UHG
UHGs security team developed an internal tool called ChaoSlingr (no longer maintained, located at https://github.com/Optum/ChaoSlingr). This was a platform designed to inject security-relevant failure scenarios into production environments. It included features like degrading DNS resolution, introducing latency across east-west traffic zones, and simulating misconfigurations. The goal wasn’t just to test resilience; it was to validate that security operations (e.g. logging, alerting, response) mechanisms would still function under duress. In effect, UHG weaponized unpredictability, making the environment hostile not just to operational errors, but to adversaries who depend on stability and visibility.
DataDog
This philosophy is gaining traction. Forward thinking vendors like Datadog have begun formalizing Security Chaos Engineering practices and providing frameworks that organizations can adopt regardless of scale. In its blog “Chaos Engineering for Security”, Datadog (https://www.datadoghq.com/blog/chaos-engineering-for-security/) outlines practical attack-simulation experiments defenders can run to proactively assess resilience. These include:
Simulating authentication service degradation to observe how cascading failures are handled in authentication and/or Single Sign-On (SSO) systems.
Injecting packet loss to measure how network inconsistencies are handled.
Disrupting DNS resolution.
Testing how incident response tooling behaves under conditions of network instability.
By combining production-grade telemetry with intentional fault injection, teams gain insights that traditional red teaming and pen testing can’t always surface. This is accentuated when considering systemic blind spots and cascading failure effects.
What ties UHG’s pioneering work and Datadog’s vendor-backed framework together is a shift in mindset. The shift is from static defense to adaptive resilience. Instead of assuming everything will go right, security teams embrace the idea that failure is inevitable. As such, they engineer their defenses to be antifragile. But more importantly, they objectively and fearlessly test those defenses and adjust when original designs were simply not good enough.
Security chaos engineering isn’t about breaking things recklessly. It’s about learning before the adversary forces you to. For defenders seeking an edge, unpredictability might just be the most reliable ally.
From Fragility to Adversary Friction
Security chaos engineering has matured from a resilience validation tool to a method of influencing and disrupting adversary operations. By incorporating techniques such as temporal deception, ambiguity engineering, and the use of disinformation, defenders can force attackers into a reactive posture. Moreover, defenders can delay offensive objectives targeted at them and increase their attackers’ cost of operations. This strategic use of chaos allows defenders not just to protect an ecosystem but to shape adversary behavior itself. This is how security chaos engineering disrupts adversaries in real time.
Decentralized Agentic AI: understanding agent communication. In the agentic space of Artificial Intelligence (AI) much recent development has taken place with folks building agents. The value of well built and/or purpose built agents can be immense. These are generally autonomous stand-alone pieces of software that can perform a multitude of functions. This is powerful stuff. It is even more power when one considers decentralized Agentic AI: understanding agent communication and security.
An Application Security (AppSec) parallel I consider when looking at some of these is the use of a single dedicated HTTP client that performs specific attacks, for instance the Slowloris attack.
For those who don’t know, the slowloris attack is a type of Denial of Service (DoS) attack that targets web servers by sending incomplete HTTP requests. Each connection is kept alive by periodically sending small bits of data. In doing so this attack keeps many connections open and holds them open as long as possible, exhausting resources on that web server because it has allocated resources to the connection and waits for the request to complete.. This is a powerful attack, one that is a good fit for a stand-alone agent.
But, consider the exponential power of having a fleet of agents simultaneously performing a Slowloris attack. The point of resource exhaustion on the target can be achieved in a much quicker timeline. This pushes the agentic model into a decentralized one that will need to allow for communication across all of the agents in a fleet. This collaborative approach can facilitate advanced capabilities like dynamically reacting to protective changes with the target. The focal point here is how agents communicate effectively and securely to coordinate actions and share knowledge. This is what will allow a fleet of agents to adapt dynamically to changes in a given environment.
How AI Agents Communicate
AI agents in decentralized systems typically employ Peer-to-Peer (P2P) communication methods. Common techniques include:
Swarm intelligence communication – inspired by biological systems (e.g. ants or bees), agents communicate through indirect methods like pheromone trails (ants lay down pheromones and other ants follow these trails) or shared states stored in distributed ledgers. This enables dynamic self-organization and emergent behavior.
Direct message passing – agents exchange messages directly through established communication channels. Messages may contain commands, data updates, or task statuses.
Broadcasting and multicasting – agents disseminate information broadly or to selected groups. Broadcasting is useful for global updates, while multicasting targets a subset of agents based on network segments, roles or geographic proximity.
Publish/Subscribe (Pub/Sub) – agents publish messages to specific topics, and interested agents subscribe to receive updates relevant to their interests or roles. This allows strategic and efficient filtering and targeted communication.
Communication Protocols and Standards
Generally speaking, to make disparate agents understand each other they have to speak the same language. To standardize and optimize communications, decentralized AI agents often leverage:
MQTT, AMQP, and ZeroMQ – these lightweight messaging protocols ensure efficient, scalable communication with minimal overhead.
Blockchain and Distributed Ledgers – distributed ledgers provide immutable, secure shared states enabling trustworthy decentralized consensus among agents.
Security in Agent-to-Agent Communication
Security in these decentralized models remains paramount. This is especially so when agents operate autonomously but communicate in order to impact functionality and/or direction.
Risks and Threats
Spoofing attacks – malicious entities mimic legitimate agents to disseminate false information or impact functionality in some unintended manner.
Man-in-the-Middle (MitM) attacks – intermediaries intercept and alter communications between agents. Countermeasures include the use of Mutual Transport Layer Security (mTLS), possibly combined with Perfect Forward Secrecy (PFS) for ephemeral key exchanges.
Sybil attacks – attackers create numerous fake entities to skew consensus across environments where that matters. This is particularly dangerous in systems relying on peer validation or swarm consensus. A notable real-world example is the Sybil attack on the Tor network, where malicious nodes impersonated numerous relays to deanonymize users (https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/winter). In decentralized AI, such attacks can lead to disinformation propagation, consensus manipulation, and compromised decision-making. Countermeasures include identity verification via Proof-of-Work or Proof-of-Stake systems and trust scoring mechanisms.
Securing Communication with Swarm Algorithms
Swarm algorithms pose unique challenges from a security perspective. This area is a great opportunity to showcase how security can add business value. Ensuring a safe functional ecosystem for decentralized agents is a prime example of security enabling a business. Key security practices include:
Cryptographic techniques – encryption, digital signatures, and secure key exchanges authenticate agents and protect message integrity.
Redundancy and verification – agents verify received information through redundant checks and majority voting to mitigate disinformation and potential manipulation.
Reputation systems – trust mechanisms identify and isolate malicious agents through reputation scoring.
Swarm Technology in Action: Examples
Ant Colony Optimization (ACO) – in ACO, artificial agents mimic the foraging behavior of ants by laying down and following digital pheromone trails. These trails help agents converge on optimal paths towards solutions. Security can be enhanced by requiring digital signatures on the nodes that make up some path. This would ensure they originate from trusted agents. An example application is in network routing. Here secure ACO has been applied to dynamically reroute packets in response to network congestion or attacks (http://www.giannidicaro.com/antnet.html).
Particle Swarm Optimization (PSO) – inspired by flocking birds and schools of fish, PSO agents adjust their positions based on personal experience and the experiences of their neighbors. In secure PSO implementations, neighborhood communication is authenticated using Public-Key Infrastructure (PKI). In this model only trusted participants exchange data. PSO has also been successfully applied to Intrusion Detection Systems (IDS). In this context, multiple agents collaboratively optimize detection thresholds based on machine learning models. For instance, PSO can be used to tune neural networks in Wireless Sensor Network IDS ecosystems, demonstrating enhanced detection performance through agent cooperation (https://www.ijisae.org/index.php/IJISAE/article/view/4726).
Defensive Applications of Agentic AI
While a lot of focus is placed on offensive potential, decentralized agentic AI can also be a formidable defensive asset. Fleets of AI agents can be deployed to monitor networks, analyze anomalies, and collaboratively identify and isolate threats in real-time. Notable potential applications include:
Autonomous threat detection agents that monitor logs and traffic for indicators of compromise.
Adaptive honeypots that dynamically evolve their behavior based on attacker interaction.
Distributed patching agents that respond to zero-day threats by propagating fixes in as close to real time as possible.
Coordinated deception agents that generate synthetic attack surfaces to mislead adversaries.
Governance and Control of Autonomous Agents
Decentralized agents must be properly governed to prevent unintended behavior. Governance strategies include policy-based decision engines, audit trails for agent activity, and restricted operational boundaries to limit risk and/or damage. Explainable AI (XAI) principles (https://www.ibm.com/think/topics/explainable-ai) and observability frameworks also play a role in ensuring transparency and trust in autonomous actions.
Future Outlook
For cybersecurity leadership, the relevance of decentralized agentic AI lies in its potential to both defend and attack at scale. Just as attackers can weaponize fleets of autonomous agents for coordinated campaigns or reconnaissance, defenders can deploy agent networks for threat hunting, deception, and adaptive response. Understanding this paradigm is critical to preparing for the next evolution of machine-driven cyber warfare.
Decentralized agentic AI will increasingly integrate with mainstream platforms such as Kubernetes, edge computing infrastructure, and IoT ecosystems. The rise of regulatory scrutiny over autonomous systems will necessitate controls around agent explainability and ethical behavior. Large Language Models (LLMs) may also emerge as meta-agents that orchestrate fleets of smaller specialized agents, blending cognitive reasoning with tactical execution.
Conclusion
Decentralized agentic AI represents an ocean of opportunity via scalable, autonomous system design. Effective and secure communication between agents is foundational to their accuracy, robustness, adaptability, and resilience. By adopting strong cryptographic techniques, reputation mechanisms, and resilient consensus algorithms, these ecosystems can achieve secure, efficient collaboration, unlocking the full potential of decentralized AI. Decentralized Agentic AI: Understanding Agent Communication.
Part 5 of: The Decentralized Cybersecurity Paradigm: Rethinking Traditional Models
InPart 4 we covered decentralized security system resilience. To wrap this series up we will cover challenges and opportunities of decentralized security in enterprises.
The cybersecurity landscape is in a state of perpetual evolution. Cyber threats are growing more sophisticated. Their frequency is also increasing. Distributed IT solutions are rapidly expanding. These trends are the main drivers. Traditional, centralized security models were once the norm. Now, they face mounting limitations. This is due to today’s dynamic IT environments. The old models are generally characterized by central points of control and a defined network perimeter. Those models now struggle to effectively protect the sprawl of cloud-based services, remote workforces, and the miriad of diverse endpoints that exist in a modern enterprise (https://www.dnsfilter.com/blog/everything-you-need-to-know-about-decentralized-cybersecurity).
The old ways worked in the past and will soon show they cannot keep up with modern day advancements. Maintaining control and visibility in modern complex ecosystems have created the need for alternative security paradigms. Among these emerging approaches, decentralized security models are gaining traction as the represent a better fit, offering a fundamentally different way to protect enterprise assets and data (https://thecyberexpress.com/why-decentralized-cybersecurity-the-road-ahead/).
Fundamental Concepts and Architectural Components
Fundamental Concepts
Decentralized security represents a paradigm where security responsibilities and controls are distributed across various entities within an ecosystem. This is fundamentally different than the traditional models focused on concentration within a single, central authority. This new approach changes security’s focus. It shifts from securing a defined network perimeter. Protective mechanisms now embed closer to assets. Identities and users also gain direct protection. Security becomes a shared responsibility. This includes different teams and business units. Decentralized models can harness this collective power. Many entities now contribute to security. They traditionally lacked a cohesive presence. This can enhance an organization’s overall security posture and resilience.
Traditional centralized approaches require dedicated security teams to manage all aspects of cybersecurity. Decentralized security empowers individual teams to make technology decisions and take ownership of securing the solutions they utilize, own, and build. After all, they have the necessary intimacy required to adequately protect these solutions, secuirty teams do not. This distribution of responsibility is particularly well-suited for today’s cloud-heavy environments, where technology adoption often occurs at the business unit level where security is either treated as an afterthought or as an add-on burden.
The following table provides a high level summary of these fundamental concepts:
Characteristic
Centralized Security
Decentralized Security
Control
Single, central team of experts, often lacking system level intimacy
Distributed across individual teams and business units that possess system level intimacy
Responsibility
Primarily with the central security team
Shared among all teams and employees; security is everyone’s responsibility
Point of Failure
Single point of failure can compromise the entire system
Distributed nature reduces the risk of a single point of failure
Scalability
Can face bottlenecks and challenges in addressing complex, distributed environments
More scalable and adaptable to the growth and complexity of modern solutions
Agility
Can lead to slower innovation and restrict technology choices for individual teams
Fosters faster innovation and provides greater technological freedom and autonomy to teams
Policy Consistency
Aims for high consistency across the organization
Requires robust policies and training to ensure consistent enforcement; risk of inconsistencies if not managed well
Threat Intelligence
Often centrally managed and disseminated
Can leverage peer-to-peer sharing for faster detection and response
Architectural Components
Several key architectural components are frequently associated with decentralized security models. Blockchain technology and Distributed Ledger Technology (DLT) provide a secure and transparent foundation for various decentralized security applications. Blockchains provide immutable chain of records, ensure data integrity and transparency, and can be used for secure data sharing and identity management (https://andresandreu.tech/the-decentralized-cybersecurity-paradigm-rethinking-traditional-models-blockchain-the-future-of-secure-data/). DLT, as a broader category, enables secure, transparent, and decentralized transactions without the need for a central authority (https://www.investopedia.com/terms/d/distributed-ledger-technology-dlt.asp). Zero-Trust Architecture (ZTA) is another important architectural component. They operate on the principle of “never trust, always verify”. ZTA mandates strict identity verification and continuous access control for every user and device, regardless of their location within or outside the network.
Finally, Cybersecurity Mesh Architecture (CSMA) represents a modern architectural approach that embodies the principles of decentralized security. This embodiment is defined by security perimeters around individual devices or users, rather than the entire network (https://www.exabeam.com/explainers/information-security/cybersecurity-mesh-csma-architecture-benefits-and-implementation/). CSMA integrates various security tools and services into a cohesive and flexible framework, with key layers focusing on analytics and intelligence, distributed identity management, consolidated dashboards, and unified policy management.
Challenges in Enterprise Adoption of Decentralized Security
Enterprises considering the adoption of decentralized security models face a unique set of challenges that span technical, organizational, and governance domains. Compounding these challenges is the reality of large enterprises moving very slowly and generally being averse to change.
A significant hurdle is integration with legacy systems. Some enterprises rely on deeply embedded legacy infrastructure built on outdated technologies and protocols. These elements may not be compatible with modern decentralized security solutions. Many legacy systems lack the necessary Application Programming Interfaces (API) required for seamless integrations. For instance, integrating blockchain technology, with its distinct data structures and cryptographic underpinnings, into traditional relational databases and/or enterprise applications can present considerable challenges. Furthermore, applying security patches and updates to legacy systems while maintaining optimal performance can be challenging, sometimes resulting in systems purposely being left unpatched (https://www.micromindercs.com/blog/data-security-challenges). The potential for disruptions to ongoing critical business operations during integration processes also poses a significant concern for enterprises.
Governance complexities represent another substantial set of challenges regarding the adoption of decentralized security. Decentralized models can introduce a lack of uniformity in security policies and their enforcement across different business units within an organization. The absence of a central authority necessitates the establishment of distributed decision-making processes and accountability mechanisms. These can sometimes be slower and more intricate to manage compared to centralized control. Ensuring consistent application of security policies, and preventing the overlooking or mischaracterization of risks, across a distributed environment requires robust and continuous communication and coordination. Data governance becomes particularly complex with decentralized security, especially when data ownership and management responsibilities are distributed across various teams, potentially leading to fragmented data silos.
Skill gaps are a key challenge. Furthermore, training requirements also pose issues. They impede widespread adoption. Specifically, this affects decentralized security. This is especially true in enterprises. Many security professionals lack expertise. Consequently, they need new skills for decentralized tech. For instance, this includes blockchain and ZTAs. Indeed, managing these technologies is difficult. These models demand specific skills. For example, cryptography expertise is often needed. Additionally, knowledge of distributed systems too. Crucially, blockchain development skills are key. However, these are often missing in teams. Therefore, enterprises must gauge training value. They question, is comprehensive training worthwhile? Ultimately, they need to upskill their workforce. Yet, this is not always a clear decision. Recruiting individuals with the necessary expertise may be a better option. Furthermore, the transition to decentralized security often requires a cultural shift within an organization.
Decentrlized security requires a true sense of shared responsibility for security among all employees. This is deeper than the rhetoric often heard when some state that security is a team sport.
Opportunities and Advantages of Decentralized Security for Enterprises
Despite the outlined challenges, the adoption of decentralized security models presents tremendous promise for enterprises seeking to enhance their cybersecurity posture and overall operational efficiency.
Improved resilience and attack surface reduction are key benefits of decentralized security.By distributing security responsibilities and controls, enterprises can build more resilient ecosystems that are less susceptible to Single Points Of Failure (SPOF). This distributed nature makes it significantly more difficult for attackers to compromise an entire system or create a major impact from one single breach. They would need to target multiple nodes or endpoints simultaneously in order to reach success.
Decentralized security also contributes to a reduction in the overall attack surface. It does so by shifting the focus from a traditional network perimeter to individual endpoints and assets. This approach aims to ensure that every potential point of ingress is protected, rather than relying on a single defensive barrier. Furthermore, decentralized security models often incorporate micro-segmentation and distributed controls, which improve an enterprise’s ability to contain security breaches and limit the extent of their impact.
Decentralized systems can also lead to improved data privacy and compliance. By distributing data across multiple storage nodes, and empowering users with greater control over their personal information, these models can enhance data privacy and reduce the risk of large-scale data breaches associated with centralized data repositories. The use of robust encryption and other cryptographic techniques further strengthens the protection of sensitive data within decentralized environments.
Decentralized identity management solutions, in particular, offer individuals more autonomy over their digital identities and the ability to selectively share their data (https://andresandreu.tech/the-decentralized-cybersecurity-paradigm-rethinking-traditional-models-decentralized-identifiers-and-its-impact-on-privacy-and-security/). Moreover, the distributed nature of decentralized architectures can aid enterprises in meeting stringent data sovereignty and compliance requirements. Examples of these are the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). Decentralized architectures can ensure that data resides within specific jurisdictional boundaries.
Finally, the adoption of decentralized security models can foster increased agility and innovation within enterprise environments. By distributing security responsibilities to individual business units, enterprises can empower them to make quicker technology decisions and innovate more rapidly. This is stark contrast to the traditional approach where these units must rely on a less agile, centralized security team. This increased technological freedom and autonomy allow teams to use the tools and solutions that best fit their specific needs without being constrained by centralized security approval processes. This in turn leads to reduced bureaucratic delays and faster time-to-market for competitive products and services.
Real-World Case Studies
Several enterprises are actively exploring and implementing decentralized security models, providing valuable case studies. In the realm of blockchain-based identity management, Estonia’s e-residency program stands out as an early adopter, securing digital identities for global citizens using blockchain technology. The “Trust Your Supplier” project, a collaboration between IBM and Chainyard, utilizes blockchain to streamline and secure supplier validation and onboarding processes. The Canadian province of British Columbia has implemented OrgBook BC, a blockchain-based searchable directory of verifiable business credentials issued by government authorities.
The adoption of ZTAs is also gaining momentum across various industries. Google’s internal BeyondCorp initiative serves as a prominent early example of a large enterprise moving away from traditional perimeter-based security to a zero-trust model. Microsoft has been on a multi-year journey to implement a zero-trust security model across its internal infrastructure and product ecosystem.
Industry analyses and expert opinions corroborate the growing importance of decentralized security. Reports indicate an increasing trend towards decentralized IT functions within enterprises, often complemented by the adoption of AI-powered security platforms (https://blog.barracuda.com/2024/04/10/latest-business-trends–centralized-security–decentralized-tech). There is a consensus on the need for enterprises to strike a strategic balance between centralized and decentralized security approaches to achieve both consistency in security protocols and the agility required to adapt to evolving threats and business needs.
Best Practices for Enterprises
Enterprises embarking on the journey of adopting decentralized security models can leverage several solutions and best practices to mitigate challenges.
Establish distributed governance frameworks. This requires a shift to federated models. A central body provides guidance. It sets overarching policies. Individual business units keep autonomy. They manage their specific domains. Clear, comprehensive documentation is paramount. Document security policies fully. Detail all roles and responsibilities. This ensures consistent security practices. It is vital across a decentralized organization. Addressing skill gaps needs a multi-pronged approach. This includes investing in targeted training. Upskill existing IT personnel. Train security staff. Focus on areas like blockchain and zero-trust. Strategic hiring of individuals with specialized expertise in decentralized security technologies and methodologies is also crucial.
When implementing specific decentralized security technologies, enterprises should adhere to established best practices. For ZTAs, deploy micro-segmentation. This isolates critical assets. Enforce Multi-Factor Authentication (MFA). Apply MFA for all access attempts. Leverage identity risk intelligence. Grant users least privilege access. Provide only the minimum necessary. For blockchain solutions, assess needs first. Ensure a proper fit. Carefully select the platform. Consider factors like scalability and privacy. A strong focus on security is vital. Regulatory compliance is also essential.
A widely recommended approach for managing the complexity of adopting decentralized security is to follow a phased implementation strategy. Start with a comprehensive security assessment. Evaluate the enterprise’s current posture. Identify specific high-risk areas. Also find business use cases. Decentralized security offers immediate benefits there. Then, initiate pilot projects. Define clear objectives and success metrics. This lets enterprises test strategies. They can refine plans in a controlled environment. Broader deployment happens afterward.
Series Conclusion: The Future of Decentralized Security in Enterprise Environments
Wrapping up this series, the adoption of decentralized security models represents a significant evolution in the realm of enterprise cybersecurity. While enterprises face notable challenges in areas such as integration with legacy systems, establishing consistent governance, and overcoming skill gaps, the potential opportunities and advantages are substantial. Decentralized security offers the promise of enhanced resilience against increasingly sophisticated cyber threats, improved data privacy and compliance with evolving regulations, and the fostering of greater agility and innovation within the enterprise. Frankly, enterprises that do not embrace this will not be able to keep pace with nefarious actors that use the same technologies to their advantage.
Looking ahead, the future of enterprise cybersecurity likely involves a strategic and balanced approach that blends the strengths of both centralized and decentralized security models. Enterprises will need to carefully consider their specific needs, risk profiles, and existing infrastructure when determining the optimal mix of these approaches. The ongoing advancements in decentralized technologies, coupled with the increasing limitations of traditional perimeter-based security, suggest that decentralized security models will play an increasingly crucial role in shaping the future of enterprise cybersecurity, enabling organizations to navigate the complexities of the digital landscape with greater confidence and resilience.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager