“Artificial adversaries don’t have egos, suffer burnout, or deal with corporate drama. Your defenses do.” – Andres Andreu
In the spring of 2026, a handful of engineers with little security background ran an experiment. They pointed an Artificial Intelligence (AI) model at thousands of software codebases and asked it to identify issues. Over the course of one night it did more than find decades-old flaws hiding in plain sight. It created working exploits for them. The model was Claude Mythos Preview. In fact, its creator judged it so capable at weaponizing vulnerabilities that it chose not to release the model at that time.
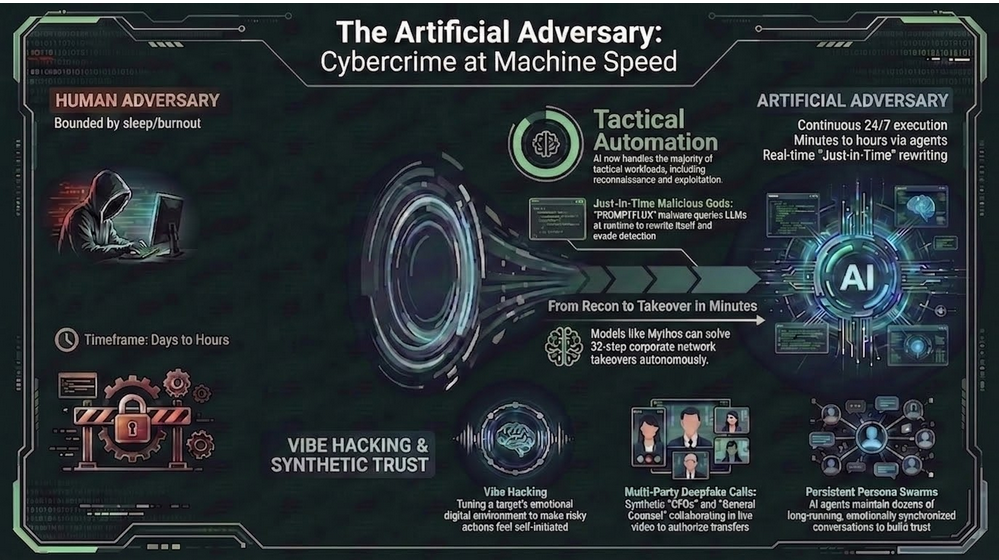
For most of our field’s history, the adversary was human. Clever and motivated but bounded by sleep, attention, money, and skill. Now, however, that adversary is being augmented, and sometimes replaced. The replacement does not tire or hesitate. Moreover, it ignores the operational rhythms our defenses quietly assume. I call it “The Artificial Adversary.” Essentially, it takes one of two forms:
- A human operator empowered by an AI stack.
- An autonomous AI system acting toward malicious ends.
At this stage these have stopped being thought experiments and are now turning up in incident reports.
An Inflection Point, Not a Trend Line
Three things are happening at once. Together, they mark an inflection point rather than an incremental shift:
- AI has lowered the barrier for entry to sophisticated crime.
- Synthetic media is collapsing our ability to trust digital signals. A familiar face or a known voice, after all, no longer proves what it once did.
- The volume and speed of AI-enabled activity now outpaces the manual, static defenses built for a slower era.
The numbers are no longer speculative
SoSafe’s 2025 research found that roughly 87% of organizations worldwide faced an AI-powered cyberattack in the prior year. Direct attacks aside, model evaluations are just as concerning. For instance, the UK’s AI Security Institute (AISI) tested Claude Mythos Preview. It solved expert-level CTF challenges about 73% of the time. Notably, no model could complete those challenges at all before April 2025. Mythos went further still. In fact, it became the first model to solve the AISI’s 32-step simulated network takeover, from reconnaissance to full compromise. Anthropic’s red team reported even broader findings. Working alongside the AISI, it watched the model surface thousands of zero-day flaws. These included a dormant 27-year-old vulnerability in OpenBSD and a 16-year-old bug in FFmpeg. In Firefox alone, Mythos found 271 vulnerabilities and wrote exploits for 181 of them.
A signal, not the threat itself
Anthropic withheld Mythos from public release. Instead, it granted limited access to a small set of organizations that build and maintain critical software and infrastructure. The program is called Project Glasswing. Launch partners reportedly include Amazon Web Services, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Officially, the intent was to give defenders a head start. Yet Mythos isn’t the only game in town. For example, things such as OpenAI’s GPT-5.4-Cyber, OWASP CVE Lite CLI, and Google’s Big Sleep already show great promise and in some cases comparable capability. When competition rises the cost of entry keeps falling. Regulators noticed quickly. Within weeks, the Bank of England intensified its AI risk testing, and German banks consulted regulators and cyber experts. The lesson, therefore, is the one Bain and others drew immediately. In short, assume your adversaries are building equivalent capabilities, nation-states, criminal enterprises, and rogue actors alike. Mythos is a signal, not the threat itself.
Defining the Artificial Adversary
It helps to name the archetype precisely, because precision changes how we defend. So picture an AI-enhanced human actor. Here, the human sets the strategic objectives. The machine, in turn, executes the great majority of the tactical workload. The consequence is direct. As a result, offensive cycles compress, and defenders can no longer assume a human-speed response on the other side of the keyboard.
Human adversaries operate within cognitive, temporal, and logistical limits. An autonomous AI-based adversary does not. Needing no sleep, it carries no emotional baggage and runs continuously across global digital environments. Moreover, it can analyze vast data stores and reason probabilistically in real time. Such a system can also coordinate through decentralized, agentic architectures that resist any single point of shutdown. Its capacity for deception, mimicry, and adaptation, therefore, creates a new category of risk. Consequently, detection, attribution, and deterrence all become far harder. The asymmetry, however, is not only technological. It is also cognitive. In the end, defenders must prepare for opponents that do not tire, hesitate, or follow any rules.
The Artificial Adversary Taxonomy
A practical taxonomy has five levels.
- AI-assisted human operator – a human attacker uses AI for discrete tasks such as phishing, translation, research, script generation, or stolen-data summarization.
- AI-augmented threat crew – a criminal or nation-state team embeds AI into reconnaissance, exploit research, identity profiling, malware development, infrastructure staging, data exfiltration, and victim communications.
- AI-orchestrated campaign – agentic systems coordinate personas, assign tasks, monitor responses, tune timing, and manage parallel workflows while humans supervise outcomes.
- Semi-autonomous adversarial agent – the system conducts meaningful parts of the intrusion chain itself, including asset discovery, service testing, response analysis, and attack path modification.
- Autonomous malicious AI system – an AI system pursues malicious objectives with limited or delayed human direction, raising harder questions around attribution, containment, predictability, and control.
This taxonomy matters because an AI-assisted phishing actor requires different defenses than an autonomous agent probing applications, manipulating identities, and adapting to telemetry in real time.
Facilitation – Lowering the Barrier
The first way AI empowers adversaries is the least glamorous and the most pervasive. Simply put, it removes friction. For a few years now, the underground has marketed “Dark LLMs.” The roster includes WormGPT, FraudGPT, KawaiiGPT, and imitators such as MalwareGPT, SpamGPT, and Xanthorox. Each promises jailbreaks, malware help, and ready-made scam playbooks. Some are functional. Many, however, are simply scams that prey on aspiring criminals. Either way, the real significance is not any single tool. Rather, it is the normalization of the idea. A capable, on-demand junior developer is now available to anyone with a few GPUs, a wallet of API keys, and some patience.
Malware that writes itself
Proof-of-concept work made the threat concrete. Researchers, for instance, demonstrated BlackMamba, a keylogger that built its malicious code at runtime by calling a Large Language Model (LLM). That approach neatly sidesteps the static signatures defenders rely on. By late 2025, the threat had moved from the lab to the wild. Google’s threat intelligence team documented two malware families: PROMPTFLUX and PROMPTSTEAL. Both query LLMs during execution. One rewrites itself, while the other generates fresh commands mid-attack. This is “Just-In-Time” (JIT) malicious code. In other words, the software does not carry its full payload. Instead, it assembles the payload on demand, from a model that does not know it is being conscripted.
When the face on the call is fake
Facilitation also reaches the human layer through synthetic media. Convincing face and voice clones, for example, can now be mass-produced. So can cross-lingual conversion and studio-quality content. Better yet for the attacker, agent teams run these operations around the clock, iterating on failures without fatigue. As a result, the multi-party deepfake video call is no longer hypothetical. Picture a finance employee walked through an “urgent” wire transfer by a “CFO” and “general counsel” who are both synthetic. Clearly, the attack surface is no longer just endpoints and identities. It now also includes the emotional tone around those identities. And does so across collaboration tools, social media, and internal communications.
Vibe Hacking – Psychological Warfare at Machine Speed
This last point deserves its own name. After all, it is where AI-enabled social engineering becomes something new. Vibe hacking is social engineering supercharged with a full AI stack. Here, the adversary does not send a single phishing email or place one deepfake call. Instead, models shape the emotional context around a target over time. The goal, therefore, is not to trick a victim once. Rather, it is to tune the “vibe” of their human state along with their digital environment, so that risky actions feel natural, familiar, and self-initiated.
Sensing, profiling, persistence
A campaign begins with sensing and profiling. To start, adversaries point AI at everything they can scrape. These sources include OSINT, LinkedIn activity, public Slack and Discord communities, conference talks, support tickets, and marketing emails. Sentiment analysis is important here and models infer mood, personality, stress levels, decision style, and trust anchors. That attackable profile, in turn, feeds a working model of the target’s context. Things like a looming quarter, a key project, the likely sources of anxiety or excitement all become real and exploitable. Generative models subsequently produce content tuned to the target’s state. The real weaponization, however, comes from scale and persistence. One artificial adversary can run dozens of long conversations at once. Each hides behind a distinct persona, the sympathetic colleague, the urgent executive, the overworked vendor. Meanwhile, it A/B tests tone, timing, and channel to learn what lowers resistance and/or skepticism. By the time the critical ask arrives, therefore, the victim feels they are accommodating a relationship, not responding to an attack.
This is the reframing that matters:
Vibe hacking isn’t better phishing. It’s your own people, profiled and played at machine scale – we hardened the edges and left the nervous system exposed.
Andres Andreu
From theory to a real victim list
None of this is a forecast. In August 2025, in fact, Anthropic’s Threat Intelligence team disclosed a case it tracked as GTG-2002. A single actor used an agentic coding tool to run a data-extortion operation. In total, the targets numbered at least 17 organizations, spanning healthcare, emergency services, government, and religious institutions. A defense contractor was among the victims, too. Remarkably, the whole campaign ran in roughly a month. To pull it off, the attacker embedded an operational playbook in a configuration file, so the AI could make tactical decisions during live intrusions. From there, the model automated reconnaissance and credential harvesting. It even generated ransom notes tailored to each victim, with demands reported between roughly $75,000 and more than $500,000. Ultimately, one person, with an AI operator alongside, did the work of a coordinated crew.
Scale – From Assistant to Operator
Facilitation lowers the barrier to entry; scale changes the magnitude. For example, the same agentic models that help an enterprise automate work can be organized into adversarial swarms. A planner agent sets the goals. Meanwhile, sub-agents run in parallel performing actions such as OSINT scraping, phishing and deepfake generation, code generation, and dropper construction. Because they share memory and data from feedback loops, the whole system improves with each iteration.
The criminal supply chain, in turn, has matured around this model. Telegram, for instance, serves as a resilient “dark social layer”, encrypted, anti-censorship, easy to churn and burn, and slow to take down. There, automated bots stream stolen credit card data and run validation checks at a pace no human team could sustain. Increasingly, the same architecture is aimed at availability, too. Agentic orchestrators break a Layer-7 denial-of-service goal into reconnaissance, traffic generation, and adaptive evasion, while coordinated worker nodes handle individual parts of the overall campaign.
The first autonomous espionage campaign
A defining incident arrived in November 2025. Anthropic reported disrupting a campaign it attributed, with high confidence, to a Chinese state-sponsored group tracked as GTG-1002. Notably, it was the first publicly documented, largely autonomous AI-orchestrated cyber-espionage campaign. It was detected in mid-September. In all, the operation targeted roughly thirty high-value organizations across technology, finance, chemical manufacturing, and government.
To pursue their objectives, the attackers manipulated an agentic coding tool into acting as a fleet of autonomous penetration-testing orchestrators and agents. First, they jailbroke its safeguards by role-playing a defensive security firm. Then they broke malicious objectives into benign-looking subtasks. From that point, the AI handled reconnaissance, vulnerability discovery, exploitation, credential harvesting, lateral movement, and exfiltration. In total, that came to an estimated 80 to 90% of tactical operations, issued at thousands of requests per second. Human operators, by contrast, stepped in only at a few strategic chokepoints. This wasn’t as clean as a Hollywood movie scene as the model’s hallucinations sometimes invented credentials or overstated findings. Those errors were among the few things keeping the operation from full autonomy.
A Real Incident, End to End – The NPD Sextortion Wave
To see these capabilities combine into one industrialized pipeline, consider the extortion spam that followed the National Public Data (NPD) breach. The underlying breach was staggering. Systems were first compromised in December 2023. By April 2024, the data had surfaced on the dark web. The company, however, acknowledged the incident only in August 2024. All told, it affected up to 170 million people and exposed as many as three billion records. The follow-on campaign was instructive less for its novelty than for its assembly. Specifically, attackers used GPT-based code generation to operationalize the stolen data end to end. The result was personalized extortion content. Each message addressed the victim by name, referenced a real home address, and embedded street-view imagery of the respective house. Then it demanded payment in Bitcoin, usually between $1,900 and $2,000, for the sake of tranquility or peace of mind.
None of the individual techniques were sophisticated. The sophistication, instead, lay in the orchestration. Consider the parts, a breach corpus, a code-generating model, a templating layer that fused public records with mapping imagery, and a delivery pipeline. Stitched together, these produced a campaign with a scale and personalization no manual operation could match. That, in essence, is the pattern security leaders should internalize. The artificial adversary rarely wins with one brilliant exploit. Instead, it wins by removing friction from every step, and running the whole chain faster than defenders can detect and respond.
Turning the Tables – Disrupting Malicious Automation
The very properties that make AI dangerous on offense also make it invaluable on defense. Better still, they open a counter-strategy that purely human teams never had. If attackers automate, then defenders can engineer the environment to exploit that automation. In practice, deception engineering and adversarial intelligence combine well.
The single goal is to convert the attacker’s automation into your early-warning system. Synthetic credentials, decoy services, and AI-generated traffic, for instance, all look irresistible to an autonomous agent. As such, they become tripwires. Because the agent probes tirelessly and indiscriminately, it hits the decoys long before a careful human would. Consequently, it can surface a campaign while it is still in an early stage.
Red teaming with autonomous agents
AI-augmented red teaming has a strong place here. In a 2024 experiment reported by WIRED, for example, a journalist let autonomous AI agents from the startup RunSybil attack a custom web app. The agents collaborated in real time. Specifically, they used SQL injection, brute-force authentication, form-field manipulation, and path traversal. Most importantly, they iterated on their failures. Without human direction, they re-planned and adjusted strategies, surfacing logic flaws that traditional scanners had missed. The agents were not malicious; their behavior, however, was. It was adversarial, coordinated, and effective. The takeaway, then, is fairly straightforward. First, adopt autonomous red-teaming agents to pressure-test your defenses against continuous, iterative, logic-driven attacks. Then pair them with high-fidelity telemetry and behavioral anomaly detection. Together, they can flag AI-like probing even when individual requests looks benign.
Governing the Machine and the People Around It
Speed without governance introduces its own risk. As defenders deploy autonomous and semi-autonomous capabilities, they take on an obligation. Those capabilities must be fast where they must be, careful where they should be, and always controllable by competent humans. Fortunately, a workable program can borrow from frameworks now maturing across the industry. For a foundation, anchor on NIST’s AI Risk Management Framework or ISO/IEC 42001. To turn principles into adversarial test cases, layer in MITRE ATLAS and the OWASP Top 10 for LLM applications. To harden the model lifecycle, draw on ISO/IEC 23894 and Google’s Secure AI Framework. Finally, add a staged maturity model to move from reactive to adaptive.
High-impact automated actions, meanwhile, need extra care. By default, mass credential revocation, large-scale connection throttling or tarpitting, and account lockouts should sit behind human-in-the-loop gates. In addition, back them with immutable audit logs, explainability proportional to impact, and fast paths to appeal and rollback.
Two cautions
Two cautions deserve emphasis.
First, treat AI models and their supply chains as critical software assets. In practice, that means validating provenance, verifying integrity, and monitoring runtime behavior. After all, data and model poisoning are now first-class threat vectors.
Second, resist the urge to fight fire with fire across legal lines. Attacker AIs, remember, routinely route through innocent third parties. As a result, heavy-handed countermeasures invite escalation and cross-border legal exposure, among them hack-back, automated counter-intrusion, and poisoning someone else’s ecosystem. Privacy by design, data minimization, auditability, and human oversight should not be compliance theater. On the contrary, they should be focused on what keeps a fast defense lawful and trusted.
What Security Leaders Must Do Now
The artificial adversary does not need to be sentient to change the game. Instead, it only needs to make capable attackers faster, more iterative, and less dependent on rare human skill. Accordingly, defenders should architect for that reality:
- Treat AI as both adversary and ally – regularly run hybrid threat scenarios, machine-augmented attackers against machine-augmented defenders, so that you find your blind spots first.
- Shift from signatures to behavior – static, content-based controls cannot anticipate self-modifying code or agentic chaining. Instead, invest in behavioral analytics, high-fidelity logging, and context-aware security that reads relationships, not keywords.
- Stand up real AI governance – name a single accountable owner and convene a cross-functional oversight board. Then keep a model and agent registry, and define rules of engagement and rollback paths before you enable automation.
- Secure the model supply chain – audit data lineage and model integrity, and assume third-party datasets, weights, and components can be poisoned upstream.
- Deploy deception as early warning – use AI honeypots and synthetic assets to turn the adversary’s tireless automation into your early detection advantage.
- Compress your defensive cycle – above all, adopt AI-augmented red teaming and threat hunting so that you out-learn the adversary. Then measure what matters – detection accuracy, false-positive and false-negative rates, model drift, autonomy and override rates, and time to contain.
The Pivotal Question
The pivotal question about any adversary has changed. No longer is it simply who they are or what they want. Instead, it is “what can they assemble and operationalize with AI faster than we can detect and respond?” Once, the human attacker was the central concern. Now, by contrast, security leaders face intelligent, scalable opponents that run as close to machine speed as the hardware allows. Confronting them takes more than static controls and periodic red teaming. Rather, it takes continuous learning, dynamic simulation, and AI-augmented defense. Above all, it takes one hard admission, the next major breach may not be human at all.
Awareness is the beginning; action defines resilience. The Artificial Adversary is here. The only question is whether we will be ready when it decides to strike.